Forecast Models
General
The following eleven forecast models are available:
- Manual forecast (based upon yearly demand)
- Simple moving average
- Exponential smoothing with level
- Exponential smoothing with level and trend
- Naive
- Adaptive exponential smoothing with level
- Regression line (least squares)
- Best fit (finds the best of the seven forecast models in a known historical period)
- Browns smoothing with level and trend
- Croston's intermittent
- Multiple regression
- Bayesian
- Life Cycle
- Rule Based
- ML Weather
All these forecast models except naive and multiple regression can be combined with periodic seasonal indexes. Multiplying the basic forecast calculated for a period with the current index value for the same period results in the final forecast. Seasonal indexes are used whenever there is seasonal fluctuation in demand. These indexes are explained in detail in Season Indexes.
Introduction
Notation
| Y | Expected yearly demand |
| N | Number of periods per year |
| Dt | Observed demand in period t |
| Lt | Estimated level in period t |
| Tt | Estimated trend in period t |
| Forecast given in period t for a period n periods ahead | |
| t=0 | First period with historical demand |
| t=h | Last period with historical demand |
| x | Number of periods used for simple moving average |
| n | Number of periods for which to make a forecast |
| a | Alpha: a smoothing constant for level,
|
| b | Beta: a smoothing constant for trend,
|
| r | Rho: a parameter used to reduce the long term trend,
|
1. Manual Forecast
The model gives an average demand per period from a fixed yearly demand. The forecast beginning in period t and valid for future periods (t + n) is given by the following formula:
![]()
2. Simple Moving Average
The concept of moving average is that observations that are close in time are also likely to be close in value. Therefore, taking an average of the points near a certain point in time will provide a reasonable estimate of the trend cycle during that period. The average eliminates some of the randomness in the data, leaving a smooth trend cycle component. The forecast model has no explicit trend, so the forecast for any future period is set equal to the average of the last x periods of observations.
The term moving average is used to describe this procedure because each average is computed by dropping the oldest observation and including the next observation. For example, suppose you decide to use a three-month moving average. The forecast for January will be calculated as the sum of demand in October, November, and December, divided by 3. In the calculation of the February forecast, October will be replaced by January.
The general term forecast based on moving average is given by the following formula:
![]()
3. Exponential Smoothing
This model applies an unequal set of weights to past data. The weights typically break down in an exponential manner from the most recent to the most distant data point, meaning that the model is taking a weighted average of past observations using weights that decrease smoothly.
The weight parameter also is called the smoothing parameter. When the smoothing parameter is set equal to 0.20, the most recent period is weighted 20%, the next recent period is weighted 16% (= 0.20 � (1 - 0.20)), and the previous period is weighted 12.8%. This is done until the oldest period is reached in this exponential calculation. The sum of these weights is arithmetically adjusted to 1.0.
If the smoothing parameter is set equal to the highest recommended value, 1.0, the model calculates the forecast for the next period to be equal to the most recent period. If the smoothing parameter is set equal to 0.0, the next periods will have no influence on the forecast, which will remain at the original level.
Formula used for calculating initial forecast value
The initial forecast value is the interception of the regression line of the historical demand. See L-1 in the exponential smoothing, corrected trend formula below.
Formulas used for calculating current forecasts
Starting from the first period in the history, the level is updated by using the following formula:
![]()
The forecast given in period t for a future period (t + n) is given by the following formula:
![]()
4. Exponential Smoothing with Level and Trend
If there is a steady trend in demand, forecasts based on moving average or exponential smoothing will lag behind the current demand. There is a need for an additional component, which helps to eliminate the lag. New values should significantly be higher or lower than the previous ones. The trend cycle T denotes an estimate of the slope of the forecast. Since there may be some randomness remaining in current demand observations, the trend T is modified by smoothing with a parameter b.
Note that the principle for updating level and trend are the same, and these respective formulas are used:
![]() ,
,
![]() .
.
Values for interception L-1 and slope T-1 are initialized by the following formulas:
Interception ![]()
![]()
Slope
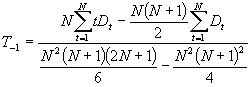
The forecast calculated in period t for a future period (t + n) is given by the following formula:
![]()
Note that the reduction factor r , which implies the trend effect, is reduced. In the long term, it slows down to zero. The r should be set close to 1.0. If r is set equal to 1.0, there will be no reduction in the trend effect.
5. Naive
Also referred to as Random Walk. This forecast just uses the previous period's sales as this period's forecast.
Formulas used for calculating current forecasts
![]()
6. Adaptive Exponential Smoothing
This model is very similar to the exponential smoothing. It is also called ARRSES: Adaptive Response Rate Single Exponential Smoothing. The difference between ordinary exponential smoothing and this model is that this model allows the value of alpha to be modified, in a controlled manner, as changes in the pattern of data occur. The formulas of this model are equal to the formulas of exponential smoothing except that the value of a (alpha) is replaced by a(t):
![]()
![]()
![]()
![]()
Formulas used for calculating current forecasts
Starting from the first period in history, the level is updated by using the following formula:
![]()
The forecast given in period t for a future period (t + n) is given by:
![]()
Starting values are:
L-1 is the same as exponential smoothing.
A-1 = B-1 = 0
The start alpha for the h/4 periods is set to the initial value. Then the alpha values are starting to get corrected. For example, if a part has 24 periods of historical demand, then the alpha is set to its initial value for the 24/4 = 6 first periods of the demand.
7. Regression
This forecast model is a straight-line fitting of the historical periods, according to the least squares fitting rule.
Regression line
![]()
Interception ![]()
![]()
Slope
Formulas used for calculating current forecasts
![]()
8. Browns Level and Trend
The model is very similar to the Exponential smoothing, corrected trend model mentioned above. The only difference is that the a and the b in the forecast equation is replaced by a b and b b. You enter a single parametera that is used according to the following equations.
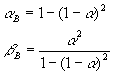
A special case is when a is set to 0 then a b=0 and b b=0
Formulas used for calculating current forecasts
The level and trend are updated through the following formulas:
![]()
![]()
The forecast given in future a future period (t+n) is given by:
![]()
Note that the reduction factor r , which implies the trend effect, is reduced; in the long term, it slows down to zero. The r should be set close to 1.0. If r is set equal to 1.0, there will be no reduction in the trend effect.
Starting values are:
The values for L-1 and slope T-1 is the same as for the Exponential smoothing, corrected trend model, as shown above.
9. Best Fit
This is a forecast model that runs every other model in competition on the last known historical demand. The model with the best result is chosen as a forecast model for this part, you can choose which error measure you want to be the base for the competition. You can select among MAE and MSE as the parameter to optimize, see Define Advance Server Settings for details on how to select optimizing measurement. The forecast models are run with different parameters, so that the parameters are also optimized.
A linear step is used to search for the optimal parameters. If we have a step size of 0.025, then the optimizing algorithm works like this: Start with parameter1 = 0, then parameter2 is increased from 0 to 1 in 0.025 steps. Then increase parameter1 by 0.05, and execute another run on parameter2. If you have only one parameter, then only the first run is executed. The step size is determined by the Advance Server Setting entry BestFitNoOfAlphaSteps or BestFitNoOBetaSteps (see below). The moving average model is executed with all possible lengths on the number of periods (2..n).
These forecast models are run when the best fit model is selected:
- Manual forecast (based upon yearly demand)
- Simple moving average
- Exponential smoothing with level
- Exponential smoothing with level and trend
- Naive
- Adaptive Exponential smoothing with level
- Regression line (least squares)
- Browns smoothing with level and trend
Every forecast model is run and the parameters are selected as follows:
Moving Average
All possible number of periods are tried from min_average_period_number..n. N = number of historical periods on this part. The default minimum average period number is 1.
- The minimum average period number ForecastModels/BestFitMovingAverageMinPeriods
Least Squares
There are no parameters to change.
EWMA (level)
Here the alpha is changed from 0.01 to 0.3 in 25 steps (default). The limits can be changed in the following Advance Server Settings entries:
- Lower alpha limit ForecastModels\BestFit\EWMA_AlpaStart
- Upper alpha limit ForecastModels\BestFit\EWMA_AlpaStop
- Number of alpha steps ForecastModels\BestFit\NoOfAlphaSteps
EWMA (level/trend)
Here the alpha is changed from 0.02 to 0.51 in 25 steps. Beta is changed from 0.005 to 0.18 in 25 steps (default). The limits can be changed in the following Advance Server Settings entries:
- The lower alpha limit ForecastModels\BestFit\EWMATREND_AlpaStart
- The upper alpha limit ForecastModels\BestFit\EWMATREND_AlpaStop
- The lower beta limit ForecastModels\BestFit\EWMATREND_BetaStart
- The upper beta limit ForecastModels\BestFit\EWMATREND_BetaStop
- Number of alpha steps ForecastModels\BestFit\NoOfAlphaSteps
- Number of beta steps ForecastModels\BestFit\NoOfAlphaSteps
AEWMA
Here the a start value of alpha is set to 0.2. Beta values are changed between 0,1 and 0,3 in 25 steps (default). The limits can be changed in the following advance server settings:
- The lower beta limit ForecastModels\BestFit\AEWMA_BetaStart
- The upper beta limit ForecastModels\BestFit\AEWMA_BetaStop
- Number of beta steps ForecastModels\BestFit\NoOfAlphaSteps
Note that there are common variables in the Advance Server Settings that decide the number of steps in the alpha and beta parameter searches.
The Rho damping is not changed. Note that if a forecast model has a seasonal profile attached, the optimalization algorithm is done with the seasonal profile applied in all calculations.
Browns level and trend
Here the alpha vales are changed between 0.01 and 0,3 in 25 steps (default). The limits can be changed in the following Advance Server Settings:
- The lower alpha limit ForecastModels\BestFit\Brown_AlpaStart
- The upper alpha limit ForecastModels\BestFit\Brown_AlpaStop
- Number of alpha steps ForecastModels\BestFit\NoOfAlphaSteps
10. Croston's Intermittent
This forecast model is a special model to be used on parts with intermittent demand (slow movers). This model calculated the occurrence of demand an the size of demand separately.
Definitions
| n | Serial number of non zero actual demand period |
| n' | Spliced serial number of non zero demand used for initialization |
|
|
Expected size of demand |
|
|
Expected inter arrival time |
|
|
Actual inter arrival time |
Installation
In the original algorithm a fair amount of data is needed to initialize the model. In many cases that amount of data is not available due to the sporadic nature of intermittent demand. An extension to the original algorithm based on a procedure to build an empirical distribution is presented here. Five historic demand occurrences are needed in order to initialize. First we need to extend the five historic demands into 25 occurrences by splicing five repetitions of the time series at hand together. Then the following equations are applied.
![]()
![]()
Recursive update
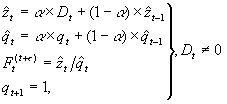
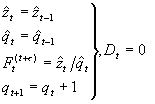
The forecast given in period t for a future period (t + n) is given by:
![]()
Note on error measures and Croston's
The ordinary metrics MAE, Value MAE, MSE and ME compare the forecast, which is an expected value for all periods, with the actual demand and is therefore correct.
MAPE, WMAPE and RME gives divide by zero error if the actual demand is zero and can therefore only be updated on non zero periods. Therefore the metric is not relevant for intermittent parts.
The PVE and Tracking Signal don�t have any meaningful interpretation for parts with intermittent demand. Therefore, the user has to disregard them
The confidence interval will be quite large since it will be around the forecast and based on the MAE metric. It is not meaningful to use it for outlier detection but it gives an idea about the variation of the mean demand for all periods.
Note on Croston's and forecast adjustments
When adjusting the forecast and using the Croston's forecast model you will also change the Expected Demand Size filed in Detail View up or down so the formula Expected Demand Size = Average Adjusted Forecast * Inter Arrival Time is valid. The user can also adjust the Inter Arrival Time field in Detail View and this will in turn change the Expected Demand Size so that the equation above is valid. The field Sys. Expected Demand Size and Sys. Inter Arrival Time in Detail view is the results of the calculations above.
11. Multiple Regression
In multiple regression there is one variable to be predicted (e.g. sales), but two ore more explanation variables (se below for the mathematical general form. Thus if sales where the variable to be forecast, several factors such as GNP, advertising, prices, competition, and time could have influence on the sales. All or some of these variables can be used to calculate the forecast for the sales of this product. Explanation variables can also be used to explain time-related effects on the sales such as seasonal changes, trading day variations, variable holiday effects etc. For example lets look at seasonal changes, and assume quarterly period version to add explanation variables for seasonal changes. Add 3 explanation variables taking these values :
| Quarter | Expvar 1 | Expvar 2 | Expvar 3 |
| 1 Quarter | 0 | 0 | 0 |
| 2 Quarter | 1 | 0 | 0 |
| 3 Quarter | 0 | 1 | 0 |
| 4 Quarter | 0 | 0 | 1 |
Multiple regression model
We start the regression from the first period where all explanation variables and the parts historical demand have data. If an explanation variable don�t have data in all forecast periods then the latest period is copied in the missing periods.
![]()
Where Yi ,X1i ,...,Xki represent the ith observations of each of the variables Y ,Xi ,...,Xi (Y is the parts consumption, the X�s are the explanation variables) respectively, b0 ,b1,...,bk are fixed but unknown parameters, and ei is the estimated error.
Solving the regression coefficients
![]()
![]()
The method of least squares is used to find the minimum sum of the squares of the error terms, in order to find b0 ,b1,...,bk to minimize.
![]()
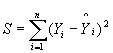
![]()
By taking partial deviates of S with respect to each of the unknown coefficients b0 ,b1,...,bk ,setting these deviates to zero, and solving a set of k equations with k unknowns to get the estimated values of b0 ,b1,...,bk.
![]()
![]()
![]()
.....
Solving the equation set AX=B is done by Gaussian elimination.
The forecast given in period t for a future period (t + n) is given by:
![]()
12. Bayesian
This forecast model is acutely 1/4 of 4 other forecast models. The 4 different models used are :
To find the parameters for the different models a best fit parameter search is preformed see Best fit. This means that we find the 'optimal' parameter set for each of the 4 models. Then this model consists of 1/4 of each of the 4 models.
Note that it is also possible to use fixed parameters for the different models in Bayesian forecast model, see Define Advance Server Settings for details.
Formulas used for calculating current forecasts
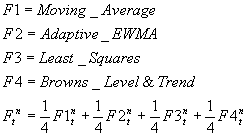
The Advance Server Settings entry ForecastModels\Bayesian\BayesianInitPeriods allows you define how many periods the part needs to have with history before the bayesian model is used. If the bayesian model is selected and the part does not have enough historical values then moving average (over all periods) is used as forecast model. Note that the part will still have bayesian as forecast model. Normal Bayesian will be used to create the forecast as soon as the part reaches the limit. Default value is 4. see Define Advance Server Settings.
13. Life Cycle
This forecast model consists of 2 separate formulas one for calculating the phase in phase and one to compute the phase out phase.
Phase in:
In parameters for phase in is Saturation level that means the anticipated level of sales when reached maturity, Start level this is the anticipated sales in the first period, the start period and the end period (period length of phase) of the phase in phase
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Then the forecast is given by:
![]()
Phase out:
In parameters for phase out is Saturation level that means the anticipated level of sales when reached maturity and the phase out period length.
![]()
![]()
![]()
Then the forecast is given by:
![]()
Saturation Update
During the phase in, mature and the phase out phases the saturation level is changed depending on if the real sales is above or below the forecasted levels. If the real sales is below then the saturation level is decreased if it is above then the saturation level is increased. This is done by exponential smoothing with the Alfa smoothing constant.
This is done according to the following formula:
![]()
![]()
![]()
![]()
![]()
14. Rule Based
This model is capable of automatically applying different forecasting models, such as Manual, Moving Average and Bayesian for Forecast Part/Group/Query based on number of historical data periods available.
The Advance Server Settings entry ForecastModels\RuleBased\Period_Start_Moving _Average allows you to define how many historical data periods the part needs to have before the Moving Average model is used. Default value is 3. If the Rule Based model is selected and the part does not have enough historical values then Manual model is used as forecast model. Note: In the detail view of the forecast part will still have Rule Based as the standard forecast model and Manual as the forecast model.
The Advance Server Settings entry ForecastModels\RuleBased\Period_Start_Bayesian allows you to define how many historical data periods the part needs to have before the Bayesian model is used. Default value is 6 If the Rule Based model is selected and the part does not have enough historical values then Moving Average or Manual is used as forecast model. Note: In the detail view of the forecast part will still have Rule Based as the standard forecast model and Moving Average or Manual as the forecast model. If number of available historical data periods is more than 6 Bayesian will be shown as the forecast model. See Define Advance Server Settings for details on how to select Advance Server Settings entry values.
15. ML Weather
This forecast model is a short term model (1-14 days) it provides a
time-series forecasting model based on weather data, it uses a non-linear
regression with high flexibility to fit any data without pre-assumptions
about actual data patterns. The model uses an external weather provider to
collect historical weather data this data together with the parts historical
data is used to train the model and weather forecast conditions
to predict the demand/forecast 14 days ahead. As with most forecast model
the result will get better with longer historical data, the model looks for
correlations between the sales/consumption and the different weather
parameters the future forecast is a result of the correlations found and the
weather forecast for then next 14 days. The Bayesian
forecast model is used to compute the forecast that extends the first 14
days trough to the last forecast period so that parts using this model
will still have the same forecast length as the other models.
Each model represents a distinct
part where the weather data is based on a geographical location where the
part is used/consumed, this location is connected to the base flow in Demand
Planning.
The weather data contains the following features:
1. Temperature
average
2. Temperature min
3. Temperature max
4. Total
Precipitation
5. Wind speed
6. Humidity
7. Total snowfall
8.
Visibility
9. Wind gust
10. Cloud cover
11. Wind direction
Note: For this model to work, Machine Learning should be enabled in the Demand Plan Server and all required setup needs to be in place
- Machine Learning Engine setup
- Needs to be synced with Demand Planning Job execution times (After the completion of Aggregate Daily Job)
- Demand Planner setup
- Demand Plan Server, Enable Machine Learning
- Base Flows, Location details
- Aggregate Daily Job, Schedule to run in daily interval
- Parts needs to have at least 180 days of history
There is also a lead time before you get the results calculated this lead time is max 7 days, reason for this is that this model requires training of algorithms and this training is only preformed once a week. Parts with less than 180 days of historical data will not be trained/calculated.