予測指標
一般的な
予測精度は、特定の予測方法が特定のデータ セットにどの程度適しているかを評価するための基準です。予測精度は、ある予測モデルを他の予測モデルよりも選択する主な理由です。予測精度は、特定のモデルのパラメーターを調整する理由でもあります。予測精度とは、現在の予測モデルが既知のデータをどれだけ正確に再現できるかを指します。
予測精度の 6 つの尺度が定義され、定量化されます。MAE、ME、MAPE、PVE、トラッキング シグナル、および Theil の U 統計。これらに加えて、回帰モデルの 1 つを実行するときに R バーの 2 乗 も使用できます。予測モデルは、これらの指標の 1 つ以上の値に基づいて評価できます。
表記
|
n |
観測数。 |
|
Dt |
期間中の観測需要 t。 |
|
Ft |
期間内の予測 t。 |
|
D |
デルタ (トラッキング シグナル平滑化パラメーター)。 |
|
et |
= Dt.- Ft |
利用可能な計測値は次のとおりです。
- MAE
- MAE の値
- ME
- RME
- MAPE
- WMAPE
- MSE
- 差異需要
- PVE
- トラッキング シグナル
- 調整係数
- パフォーマンス係数
- Rの 2 乗
- R バーの 2 乗
- サービス レベル
-
フィル レート サービス
MAE
MAE は平均絶対誤差の略語です。式は次のとおりです。
![]()
この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
MAE の値
MAE の値は、MAE に項目の在庫評価額を掛けた値です。MAE 値が最も高い予測項目は、精度の向上に最も役立つ候補です。
ME
ME は平均誤差の略語です。式は次のとおりです。
![]()
正の誤差と負の誤差は互いにオフセット傾向があるため、ME 基準は制限される可能性があります。実際、ME は、予測バイアスとも呼ばれる、体系的な予測不足または予測過剰があるかどうかのみを通知します。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
RME
RME は相対平均誤差の略語です。式は次のとおりです。
<![if !msEquation]> <![if !vml]>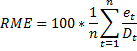 <![endif]><![endif]>
<![endif]><![endif]>
正の誤差と負の誤差は互いにオフセット傾向があるため、RME 基準は制限される可能性があります。実際、RME は、予測バイアスとも呼ばれる、体系的な予測不足または予測過剰があるかどうかのみを通知します。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)RME が最も高い品目は、予測バイアスが最も高い品目です。
予測の偏りは、常に楽観的 (RME がマイナスの予測を上回っている) または悲観的 (RME がプラスの予測を下回っている) であることを示しているため、好ましくありません。
MAPE
MAPE は平均絶対パーセント誤差の略語で、式は次のとおりです。
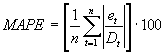
MAPE は、各項目の予測における相対的な不正確さを表します。MAPE が最も高い項目は、予測精度の向上によるメリットが得られます。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
WMAPE
WMAPE は加重平均絶対パーセント誤差の略語で、式は次のとおりです。

WMAPE は、各項目の予測における相対的な不正確さを表します。絶対誤差が大きい期間には、絶対誤差が小さい期間よりも大きく加重されます。これにより、絶対誤差が小さい期間ではなく、パーセント誤差が非常に大きい測定が支配的になります。WMAPE が最も高い項目は、予測精度の向上によるメリットが得られます。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
MSE
MSE は平均 2 乗誤差の略語で、式は次のとおりです。
<![if !msEquation]> <![if !vml]>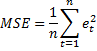 <![endif]><![endif]>
<![endif]><![endif]>
MSE は、各項目の予測における不正確さの 2 乗を表します。MSE が最も高い項目は、予測精度の向上によるメリットが得られます。MSE には、単一の大きな予測誤差を持つ品目のほうが、予測誤差は同じであっても測定期間にわたって誤差がより均等に分散している品目よりもペナルティが大きくなるという特性があります。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
差異需要
これは需要ベクトルの平均からの分散であり、式は次のとおりです。
<![if !msEquation]><![if !vml]>![]() <![endif]><![endif]>
<![endif]><![endif]>
差異は品目の需要パターンの変動を表します。需要の変動が大きい項目は通常、予測が難しく、特別な注意が必要になる場合があります。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
PVE
PVE は、分散説明率の略語です。式は次のとおりです。
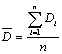
![]()
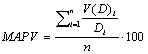
![]()
PVE は、需要の固有の変動のうち、予測モデルによって説明される部分を示します。PVE は、需要の変動性の変化を調整するため、時間の経過とともに予測が良くなっているか悪くなっているかを示します。これは優れたベンチマーク基準でもあります。PVE がゼロ未満の場合、予測は実際には需要の変動を増加させます。この場合、使用する予測モデルを変更するか、パラメーターを調整します (アルファまたは移動平均期間の数を増やします)。
この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
トラッキング シグナル
トラッキング シグナルは、バイアスを監視し、需要パターンの変化に反応するための手段です。高いトラッキング シグナル (つまり、0.6 超) は、予測に体系的な誤差または偏りがあることを示唆しています。デルタ値が低いほど、誤報のリスクが低くなります (デルタ値が高い場合よりも警報が遅く鳴ります)。デルタ値は 0.1 ~ 0.3 が推奨されます。式は次のとおりです。
![]()
![]()
![]()
この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
調整係数
調整係数、式は次のとおりです。
![]()
![]()
<![if !msEquation]> <![endif]>
調整係数は、ユーザー調整済予測 (過去の予測) と純粋に数学的な予測 (説明予測) の差を表します。調整係数が 10 の場合、ユーザー調整済予測は純粋に数学的な予測よりも 10% 正確であることを意味し、-10 の場合、純粋に数学的な予測の方が正確であることを意味します。マイナスの調整係数が高い項目は、純粋な数学的予測 (非干渉) のメリットが得られます。この式は最新の履歴期間から実行され、予測誤差期間で指定された期間数だけ遡って計算されます (n = 予測誤差期間)。(一般的なサーバー データの入力を参照)
パフォーマンス係数
パフォーマンス係数の式は次のとおりです。
<![if !vml]><![endif]>
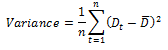
![]()
ここで、差異は品目の需要パターンの変動です。需要変動が大きい項目は予測が難しいため、特別な注意が必要です。
MSE は平均 2 乗誤差の略で、各項目の予測の不正確さの 2 乗を表します。MSE が最も高い項目は、予測精度の向上によるメリットが得られます。
パフォーマンス係数が高い項目は注意深く取り扱う必要があります。需要変動と比較すると、このような項目の予測精度は低くなります。パフォーマンス係数が1
を超える場合、予測からの実際の需要偏差が平均からの需要変動よりも大きいことを意味します。この式は最新の履歴期間から実行され、n は過去の予測誤差期間で指定された期間数です (n =予測誤差期間)。(一般的なサーバー データの入力を参照)
Rの 2 乗
R2 とも呼ばれます。この指標は、予測モデル回帰 (最小 2 乗) または重回帰が使用される場合にのみ使用されます。R 2 乗は、回帰 (最小 2 乗モデルを使用する場合) または選択された説明変数 (重回帰を使用する場合) によって説明 (考慮) される、過去の需要の分散の割合として解釈すると便利です。
表記:
|
Yi |
需要変数の回帰推定。 |
|
Di |
需要変数。 |
<![if !vml]>![]() <![endif]>
<![endif]>
<![if !msEquation]> <![if !vml]>![]() <![endif]>
<![endif]>
サービス レベル
サービス レベルは、予測誤差期間内に製品が顧客に提供可能であった日数の割合を示します。その日に販売が報告されず、その日の終わりに在庫数が 0 の場合、その日は売り切れ日として扱われます。サービス レベルの測定は次のように計算されます。
<![if !msEquation]> <![if !vml]>![]() <![endif]><![endif]>
<![endif]><![endif]>
フィル レート サービス
フィル レート サービスは、予測誤差期間内にエンティティが満たす顧客の需要数量の割合を示します。これは、納入された数量と顧客が要求した合計数量の比率となり、ユーザーは顧客の製品のアベイラビリティによって獲得した販売の割合を把握することができます。フィル レート サービスの測定は次のように計算されます。
<![if !vml]>![]() <![endif]>
<![endif]>
<![if !msEquation]> <![if !vml]>![]() <![endif]><![endif]>
<![endif]><![endif]>
損失数量は、売り切れ日に予想される需要です。その日に販売が記録されず、その日の終わりに在庫/手持ち数量が 0 の場合、その日は売り切れ日として扱われます。売り切れ日の損失数量は、システム予測または調整済予測を使用して計算できます。サーバー詳細設定では、ユーザーは上記の 2 つのオプションから、売り切れ日数の補償 (損失数量) 計算に最も適したオプションを選択できます。システム予測は、売り切れ日の補償計算のデフォルト方法になります。
<![if !msEquation]> <![endif]>