Data Services¶
Data Services enables Data citizens to efficiently use Data from across Data estates that can be used for BI purposes. This is done by providing an integrated set of tools to acquire, transform, and ultimately serve that Data.
During this release, IFS Data Services is a combination of the main services below.
- Data Lake Service
- Data Pipeline Service
These are multi-tenant services. The main IFS Cloud Web functionalities launched during this release provide the capability to load Data into the Data Lake, enrich, cleanse and transform via a Data Pipeline for specific use cases (ESG /Copilot). Data Services related functionalities are dependent on the IFS.ai Platform.
Data Lake¶
The main Datastore for the Data Services is a Data Lake (Azure Data Lake Gen 2 storage). This Data Lake will hold Data based on different requirements (Analytics-based solutions, documents for indexing).
Raw Data is ingested into the Data Lake, and the Data is enriched and transformed via a Data Pipeline for specific use cases of ESG /Copilot. This is done using Python scripts on the Spark cluster, and the process is orchestrated by Argo Workflow. The Workflow is initiated through a Workload Job Definition via IFS Cloud web.
Data Pump¶
The Data Pump will do the actual data movement and generation of Parquet files. It reads Data from the Oracle database. The created Parquet file is sent to the Data Lake service and then to the specific Data Lake.
High-Level Architectural Overview¶
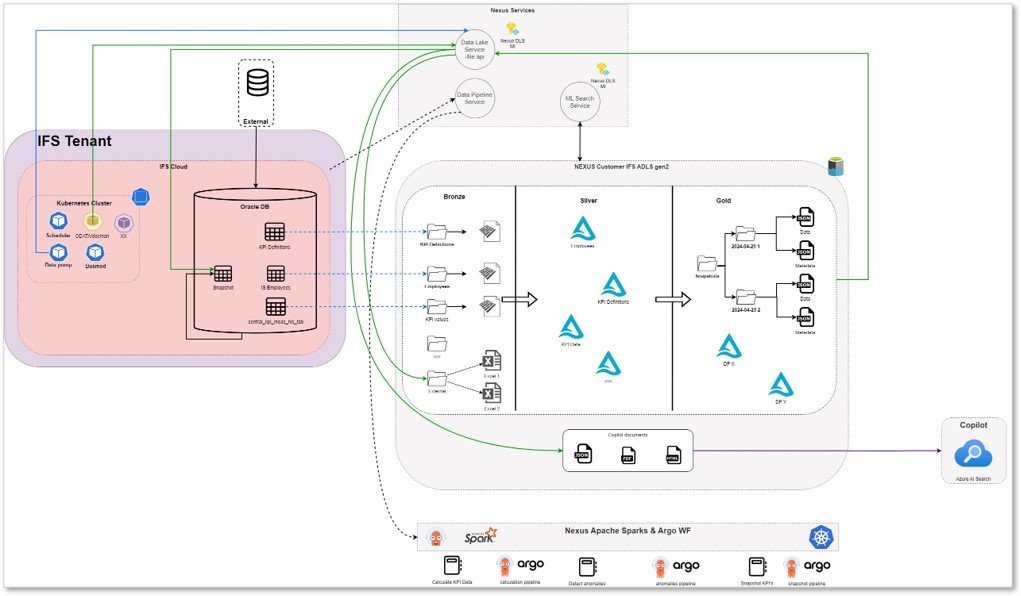
Data Lake Service¶
Data Lake Service can be used to Upload or Download the specified files from/ into Cloud Storage, Add, Update, and Get metadata-related details in a Cloud Storage, and List Down the storage hierarchy according to a given container and for a given path as well within a Cloud Storage (currently supporting only the Azure Data Lake Storage). Tenant information is determined by the service. This service securely communicates with tenant-specific Data within the IFS.ai Platform. Data Lake Service abstracts away the actual implementation of the Data Lake (ADLS Gen 2).
Read more about Data Lake Service.
Data Pipeline Service¶
Data Pipelines Service is used to start a Data Pipeline (Argo Workflow) that can orchestrate several scripts. It determines the tenant in the same way similar to the Data Lake Service (using the access token info). The Data Lake connection details are passed into the Workflow and the Workflow passes it to the script, therefore script has information to access the Data Lake.
Argo Workflow¶
Argo Workflow is used as an Orchestration engine to run Spark applications in the required manner (sequential or parallel). This is a general-purpose workflow engine for Kubernetes which is available in the IFS.ai Platform.
Read more about Data Pipeline Service and Argo Workflow.
Workload Job Definitions¶
The Workload Job Definitions page in IFS Cloud Web can be used to start a Data Pipeline via the Data Pipeline service. A Workload Job Definition consists of Parquet Data Sources and Argo Workflows (Actions).
Read more about Workload Job Definitions.
Spark Operator¶
A Spark cluster is required to execute the script that defines the Data processing logic. The Apache Spark operator is responsible for provisioning the Sparks cluster based on the request.
Read more about Spark Operator.
Prerequisites¶
Read more about prerequisites for the Workflows and Workload Job Definitions.