| Foundation1 / Development Guide / Br And A / Develop Is / Storage Layer Dev / Incremental Load Development / |
Data Mart access of an Information Source is based on snapshot tables, either Materialized Views or ordinary tables acting as snapshot tables supported by an incremental load framework. This page deals with development of support for incremental load of Fact and Dimension entities. In most cases the focus will be to add support for incremental load of Fact entities. There can however be some rare cases where also dimension entities support incremental load. The framework is general and thus handles incremental load in the same way for dimensions and facts.
To get a general overview please refer to Incremental Load of Information Sources
Note: Development of incremental load for an entity is not supported by IFS Develop Studio. Only Data Mart Access based on Materialized Views is supported by the tool.
The solution for incremental load can be summarized with the following picture:
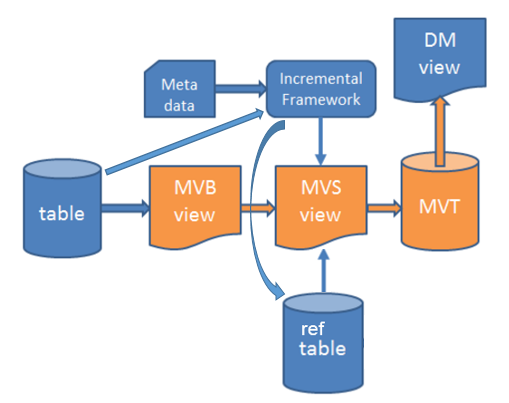
Figure 1: Incremental Load Solution Overview
The MVS view is created by the framework.
The first step is to perform a table dependency analysis with the goal to find all tables that affect the contents of the selected entity information.
This case is actually the same as first creating the MVB view and then performing an analysis using that view as a source.
It will be assumed that there is an existing Materialized View. So the idea
is now to develop new Data Mart access and replace the Materialized View access
with access of an incrementally loaded table. As an example the fact entity
FACT_CUSTOMER_ORDER_LINE is used.
Looking into Data Mart view FACT_CUSTOMER_ORDER_LINE_DM leads to
the references Materialized View CUSTOMER_ORDER_LINE_MV.
Next step will be to start analyzing the Materialized View in order to find
the source tables. First look at the
tables used in the FROM clause.
SELECT
...
col.order_no || '^' || col.line_no || '^' || col.rel_no || '^' || TO_CHAR(col.line_item_no) objid
FROM CUSTOMER_ORDER_LINE_TAB col, CUSTOMER_ORDER_TAB co
WHERE col.order_no = co.order_no;
It is obvious that there are two source tables to consider:
CUSTOMER_ORDER_TABCUSTOMER_ORDER_LINE_TABApart from this it is necessary to check all sub-selects and function calls.
SELECT
-- original keys --
col.order_no order_no_key,
col.line_no line_no_key,
col.rel_no rel_no_key,
col.line_item_no line_item_no_key,
-- measure items --
col.buy_qty_due buy_qty_due,
col.qty_assigned qty_assigned,
col.qty_picked qty_picked,
col.qty_short qty_short,
col.qty_shipped qty_shipped,
col.qty_shipdiff qty_shipdiff,
col.qty_returned qty_returned,
col.qty_invoiced qty_invoiced,
col.revised_qty_due qty_inventory,
ABS(col.buy_qty_due - col.qty_shipped) inv_qty_incomplete,
col.base_sale_unit_price base_sale_unit_price,
col.base_unit_price_incl_tax base_unit_price_incl_tax,
Customer_Order_Line_API.Get_Base_Sale_Price_Total(col.order_no, col.line_no, col.rel_no, col.line_item_no) net_amount_base,
Customer_Order_Line_API.Get_Base_Price_Incl_Tax_Total(col.order_no, col.line_no, col.rel_no, col.line_item_no) gross_amount_base,
Customer_Order_Line_API.Get_Sale_Price_Total(col.order_no, col.line_no, col.rel_no, col.line_item_no) net_amount_curr,
Customer_Order_Line_API.Get_Sale_Price_Incl_Tax_Total(col.order_no, col.line_no, col.rel_no, col.line_item_no) gross_amount_curr,
col.buy_qty_due * col.price_conv_factor * col.base_sale_unit_price net_amount_before_disc_base,
col.buy_qty_due * col.price_conv_factor * col.base_unit_price_incl_tax gross_amount_before_disc_base,
...
Only a part of the Materialized View is shown above. It will be
necessary to analyze how the functions Get_Base_Sale_Price_Total,
Get_Base_Price_Incl_Tax_Total etc are defined. This work can be rather
time consuming due to complexity of the logic and the number of method calls
that are performed. There is no tool that can extract the dependent tables so
the analysis has to be made manually.
Analyzing the function calls in this case leads to that the following tables are found as potential source tables:
CUST_ORDER_LINE_TAX_LINES_TABCUST_ORDER_LINE_DISCOUNT_TABRENTAL_OBJECT_TABNote: This is a
table in the RENTAL component and the
ORDER component has a dynamic dependency to
RENTAL
In the analysis process some tables were neglected. In most cases it is not necessary to consider function calls related attributes/columns that define dimension identities or dimension keys.
More important is to figure out how the business logic affects different tables. It might be that some tables can be skipped if changes are always reflected by changes in some other tables. The general rule is to reduce the number of source tables.
Next step will be to define a dependency structure. This is also a manual
step but rather easy once the source tables have been found. For
FACT_CUSTOMER_ORDER_LINE the main source tables
are CUSTOMER_ORDER_TAB and CUSTOMER_ORDER_LINE_TAB.
These table are the top most tables in the structure.
Now there are two possible ways of defining the structure
CUSTOMER_ORDER_TAB is the
top table and CUSTOMER_ORDER_LINE_TAB is a child tableCUSTOMER_ORDER_TAB and CUSTOMER_ORDER_LINE_TAB
are top tables. Please refer to the Incremental Load of Information Sources Overview for more information. The general rule is to define the top tables such that as few records as possible are affected by changes in the table structure. In the current example the suggested model will be to keep both mentioned tables as top source tables.
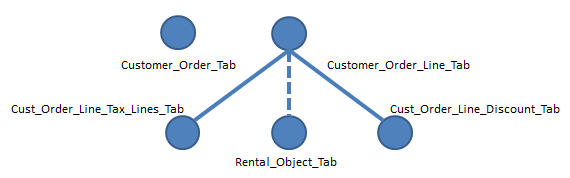
Figure 2: Table Dependency Structure - Customer Order Line
After having defined the table dependency structure, a SELECT statement
should be written that supports incremental refresh. Incremental refresh is
based on reading the source view , MVS, with conditions that takes into account
the key tables associated with the top level source tables.
SELECT * from CUSTOMER_ORDER_LINE_MVS f WHERE EXISTS ( SELECT 1 FROM <CUSTOMER_ORDER_TAB> s1 WHERE f.order_no_key = s1.order_no) UNION SELECT * FROM CUSTOMER_ORDER_LINE_MVS f WHERE EXISTS ( SELECT 1 FROM <CUSTOMER_ORDER_LINE_TAB> s2 WHERE f.order_no_key = s2.order_no AND f.line_no_key = s2.line_no AND f.rel_no_key = s2.rel_no AND f.line_item_no_key = s2.line_item_no)
Note: The framework can create the refresh statement if it is not supplied via the model file. It is however recommended to manually create this statement, to make sure that it really is correct, that the performance is ok etc.
Since, in the example, there are two top source tables the framework will during processing create one key table for each one of these tables. The name of the key table is unknown, i.e. it is created during the processing, which makes it necessary to define a key table placeholder.
CUSTOMER_ORDER_TAB>EXISTS statement
with a sub select against the key placeholder table.UNION statement to separate each top source table
based SELECT statement.Information Source Customer Order Line will be referenced as example entity on this page. The complete model file, as developed in IFS Developer Studio, can be downloaded if needed.
This MVB view is the base view and it is more or less looks the same as the
SELECT part of a Materialized View definition. For a case where a
Materialized View based solution is to be replaced with a incremental load
solution, consider the following:
FACT_CUSTOMER_ORDER_LINE_DM view the MV name is
CUSTOMER_ORDER_LINE_MV.SELECT part of the MV to a new file with the
name Mvb_<Component><Entityclientname>.apv, e.g.
Mvb_OrderFactCustomerOrderLine.apvNote: The file
will only be used as an initial version that can facilitate creating the
model in IFS Developer Studio. If the view has all necessary columns, security
filters and performs well, it is a very good starting point when
transforming the information to a model. From the model a new version will
be created and then it is easy to compare the versions and investigate
differences.
IFS Developer Studio does not support reverse engineering of incremental
definitions but the entity can of course be reverse engineered in order to
get all attributes and other definitions in place. Then the model will have
to modified by adding properties etc and for incremental support there is a
special section that has to added manually.
CUSTOMER_ORDER_LINE_MVBThe name never includes FACT_ or DIM_
The identity is be default generated as a concatenation of keys, e.g. <key1>||'^'||<key2>||'^'||...||'^'||<keyN>. It is possible to override this definition with a model property.
Dimension
entities normally have a column names ID that defines the
unique key.
...
DEFINE MODULE = ORDER
DEFINE MVB_VIEW = CUSTOMER_ORDER_LINE_MVB
DEFINE LU = BiFactCustomerOrderLine
...
TRUNC(col.real_ship_date + col.delivery_leadtime) actual_delivery_date,
TRUNC(NVL(col.real_ship_date, col.date_entered)) reporting_date,
-- unique key
col.order_no || '^' || col.line_no || '^' || col.rel_no || '^' || TO_CHAR(col.line_item_no) objid
FROM CUSTOMER_ORDER_LINE_TAB col, CUSTOMER_ORDER_TAB co
WHERE col.order_no = co.order_no
WITH read only;
COMMENT ON TABLE &MVB_VIEW
IS 'LU=&LU^PROMPT=Bi Fact Customer Order Line^MODULE=&MODULE^';
------------------------------------------------------------------------------
-- Make sure to create the source view (MVS) at this point but only if there
-- are any entities that have been registered to use the MVB view.
-- The reason is to be able to handle upgrades that affects the source view but
-- not the incremental metadata.
------------------------------------------------------------------------------
BEGIN
Is_Mv_Util_API.Create_Mvs_View('&MVB_VIEW');
COMMIT;
END;
/
UNDEFINE MODULE
UNDEFINE MVB_VIEW
UNDEFINE LU
The example above shows the unique key column with alias OBJID,
defining a unique identifier for the fact entity
FACT_CUSTOMER_ORDER_LINE.
Note: If only the Online view exists it is not possible to just copy the definition of that view. It is necessary to make sure that client values, user specific values and security definition are taken care of. For more information please refer to storage layer development of dimensions or facts.
Note: The MVB view definition will contain a call to create the MVS view. If no entitiy has been registered to use the MVB view when the MVB file is deployed, the MVS view will not be created. The reason for creating the MVS view is that a change to the MVB view will affect the MVS view but not necessarily the incremental metadata. The MVS view is also created when the incremental metadata is deployed, since there might be criteria definitions that affects the MVS view.
The complete MVB definition example for FACT_CUSTOMER_ORDER_LINE can be downloaded if needed.
Note: The
MVB view
should not have columns that do not exist in the MVT table since this means that
there is information in the MVB that will never get stored in the
MVT.
The MVT table should not have columns, except for the created date column (MVT_CREATED_DT), that do not exist in the
MVB view since
this will lead to an error since columns will be selected based one the MVT
table. The MVS view is always created by taking the column names from the
MVT but fetching from the MVB view. See
Installation and
Deployment Considerations for more information
Note: IFS Developer Studio will create the storage table, called MVT, from the model file. The below instructions should be taken lightly
The following instructions only apply if for some reason the MVT is created manually, something that is not encouraged anymore:
BEGIN
Is_Mv_Util_Api.Create_Mvt_Table_Gen_Stmt(mvb_view_name_ => 'CUSTOMER_ORDER_LINE_MVB',
mv_table_name_ => 'CUSTOMER_ORDER_LINE_MVT');
END;
This call result in an output as follows:
Run Following command to view the statement. Note that it is required that the global execution parameter LOG_DURING_EXECUTION is set to TRUE in BA Execution Parameters SELECT * FROM XLR_LOG_LARGE_STORE_TAB WHERE trace_id = 'RLOG-'||(SELECT MAX(TO_NUMBER(REPLACE(trace_id,'RLOG-',''))) FROM XLR_LOG_LARGE_STORE_TAB) ORDER BY LINE DESC
Run the statement and extract the CREATE TABLE definition from
the CLOB_DATA column.
DEFINE MVT_TABLE = CUSTOMER_ORDER_LINE_MVT DECLARE columns_ Database_SYS.ColumnTabType; column_ Database_SYS.ColRec; table_name_ VARCHAR2(30) := '&MVT_TABLE'; BEGIN Database_SYS.Reset_Column_Table(columns_); Database_SYS.Set_Table_Column(columns_,'ORDER_NO_KEY', 'VARCHAR2(48)', 'N'); Database_SYS.Set_Table_Column(columns_,'LINE_NO_KEY', 'VARCHAR2(16)', 'N'); Database_SYS.Set_Table_Column(columns_,'REL_NO_KEY', 'VARCHAR2(16)', 'N'); Database_SYS.Set_Table_Column(columns_,'LINE_ITEM_NO_KEY', 'NUMBER', 'N'); ... ... Database_SYS.Set_Table_Column(columns_,'OBJID', 'VARCHAR2(252)', 'Y'); Database_SYS.Set_Table_Column(columns_,'MVT_CREATED_DT', 'DATE', 'N'); Database_SYS.Create_Or_Replace_Table(table_name_, columns_, '&IFSAPP_DATA', NULL, TRUE); END; / UNDEFINE MVT_TABLE
Note: The column MVT_CREATED_DT has been
added. This column is very important since it contains the date and timestamp
when a row was created in the MVT table. The ETL process in IFS Analysis
Models
needs this date to be able to perform incremental transfer of records from the
MVT table to the stage table in the data warehouse.
Please realize that the MVT_CREATED_DT column will be automatically added if IFS
Developer Studio is used.
Consider the following:
ORDER_NO_KEY, LINE_NO_KEY,
REL_NO_KEY and LINE_ITEM_NO_KEY have been defined using
e.g. Database_SYS.Set_Table_Column(columns_,'ORDER_NO_KEY', 'VARCHAR2(48)', 'N');
where the last parameter defines that the column can not be NULL.Make sure that handle this in all necessary files , i.e. in the CDB, UPG and CRE file
The constraint will be named <mvt_table_name>_PK,
e.g. CUSTOMER_ORDER_LINE_MVT_PK
MVT_CREATED_DTThe index will be named <mvt_table_name>_MVX,
e.g. CUSTOMER_ORDER_LINE_MVT_MVX
Indexes are defined in the model according to the following syntax:
indexinfo {
indexes {
index on columns DimCustomerId;
index on columns DimSupplierId;
index on columns DimInventoryPartId;
}
}
The complete MVT definition example for FACT_CUSTOMER_ORDER_LINE can be downloaded and used as template.
Note: The MVB view and the MVT table should have matching columns except for the create date column, MVT_CREATED_DT, that only exists in the MVT. See Installation and Deployment Considerations for more information
The framework will make sure to create the view called MVS, i.e. the source view that reads from the base view (MVB) when inserting into the incremental load table (MVT).
When the MVS view is created it will for a given entity add the registered MVT column name, i.e. MVT_CREATED_DATE_COL_NAME, as the alias for SYSDATE. Thus the column name defined via MVT_CREATED_DATE_COL_NAME in the MVT will contain the timestamp when a row was saved in the table.
Note: IFS Developer Studio will always create the timestamp column with the name MVT_CREATED_DT as the last column in the MVT table definition. Thus in the snapshot metadata the property MVT_CREATED_DATE_COL_NAME will get that column name as value. The MVS view is created based on column names in the MVT but fetching from the MVB. See Installation and Deployment Considerations for more information.
In order for the framework to keep track of changes in source tables it is necessary to create an associated Materialized View for each one of the source tables. The MV is named CMV and it means Check MV, i.e. a MV that checks/keeps track of the latest rowversion/timestamp.
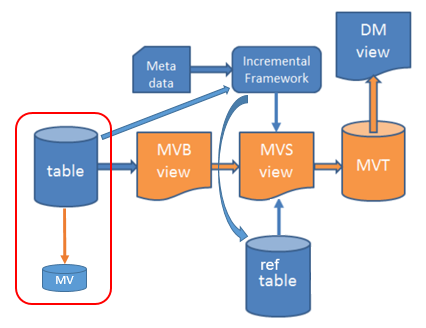
Figure 3: Incremental Load - using Materialized View to
store ROWVERSION
ROWVERSION from the source tableROWVERSION must be of
DATE type.ROWVERSION column, it must be added and taken care
of by the business logicROWVERSION of data type NUMBER exists, it is necessary to either modify
the data type to DATE or to add a new column of DATE type that has the same
meaning as ROWVERSION but expressed as a date with timestamp. In both cases this leads to changes to the business
logic.ROWVERSION column in
the source table
ROWVERSION
in a source tablesROWVERSION.ROWVERSION.The CMV file is named Cmv_<component><Entityclientname>.CRE e.g. Cmv_OrderFactCustomerOrderLine.CRE
Below follows a definition of a Materialized View that gets the maximum
ROWVERSION from CUSTOMER_ORDER_TAB
DEFINE MV_NAME = CUST_ORD_CHK_MV
DEFINE SOURCE_TABLE = CUSTOMER_ORDER_TAB
DECLARE
stmt_ VARCHAR2(32000);
BEGIN
Database_SYS.Remove_Materialized_View('&MV_NAME',TRUE);
stmt_ :=
'CREATE MATERIALIZED VIEW &MV_NAME
BUILD DEFERRED
USING NO INDEX
REFRESH COMPLETE ON DEMAND
AS
SELECT MAX(ROWVERSION) MAX_ROWVERSION
FROM &SOURCE_TABLE';
EXECUTE IMMEDIATE stmt_;
IS_MV_REFRESH_INFO_API.Clear_Refresh_Info('&MV_NAME');
END;
/
UNDEFINE MV_NAME
UNDEFINE SOURCE_TABLE
About files:
Note: The file creating CMVs can be manually deployed in a development situation. The file contains instructions how to handle the manual case. For all other cases it is necessary to run the IFS Installer that will generate and execute a proper database installation template that performs all necessary actions.
Note: The CMV file generated by IFS Developer Studio should be used as the template when creating CDB/UPG files.
The complete CMV definition example for FACT_CUSTOMER_ORDER_LINE can be downloaded and used as template.
Also consider the section about handling of dynamic source table references.
The Materialized Views that are needed to store the current max value of
ROWVERSION in the referenced source tables needs to be refreshed to
have up-to-date content.
The incremental load framework will, during the incremental processing, always refresh any referenced Materialized Views that are not FRESH. This ensures that the incremental load is based on accurate information.
It is however possible to set up a scheduled task that takes care of keeping all the referenced Materialized Views up-to-date. The benefit of doing this is to reduce the time for the incremental load processing.
In some cases the table dependency analysis will lead to that it is very difficult to define a dependency path between the tables. Since it is recommended to keep the number of tables in the dependency structure to a minimum, the framework provides a possibility to define source views that are associated with a source table. It might also be so that the source table is rather general and that only a sub set of the existing records have to be considered. In order to handle the filtering, thus reducing the number of rows to check for updates, a source view can be defined. When the framework is processing a source table, it will check if one or more associated source views have been defined and if so, use these views to check for updates instead of using the source tables.
A example is the fact
FACT_CUSTOMER_ORDER_LINE. The dependency
analysis gives at hand that there is a dependency to the source table
RENTAL_OBJECT_TAB. This table contains rental information of different
types and it is only necessary to handle rentals related to customer orders.
A source view is defined. The parent table according to the analysis is
CUSTOMER_ORDER_LINE_TAB so it is natural trying to connect
RENTAL_OBJECT_TAB with CUSTOMER_ORDER_LINE_TAB using the
parent table keys. We also want to limit the number of rental objects by
defining a filter.
-------------------------------------------------------------
-- Source view related to changes in RENTAL_OBJECT_TAB
-- Means that this view should be placed in RENTAL component
-------------------------------------------------------------
DEFINE VIEW = RENTAL_OBJECT_BIS
PROMPT Creating snapshot source view &VIEW
CREATE OR REPLACE VIEW &VIEW AS
SELECT order_ref1 order_no,
order_ref2 line_no,
order_ref3 rel_no,
TO_NUMBER(order_ref4) line_item_no,
rowversion rowversion
FROM rental_object_tab
WHERE rental_type = 'CUST ORDER'
WITH READ ONLY;
COMMENT ON TABLE &VIEW
IS 'LU=&LU^PROMPT=Rental Object^MODULE=&MODULE^';
Some observations/comments:
_BIS, e.g.
Business Intelligence Source viewNote: From Applications 9 it will be necessary to define
the BIS view in a VIEWS file. This view can be regarded as
a server only view which means that the annotation @ServerOnlyAccess
could be used.
Below is an example of a VIEWS file.
@ServerOnlyAccess
VIEW Rental_Object_Bis IS
Prompt = 'Rental Object'
SELECT order_ref1 order_no,
order_ref2 line_no,
order_ref3 rel_no,
TO_NUMBER(order_ref4) line_item_no,
rowversion rowversion
FROM rental_object_tab
WHERE rental_type = 'CUST ORDER';
Note: The incremental load specific metadata file is yet
to be defined. How to more in detail define this file can be found on a page
called Incremental Load Specific Metadata.
Since IFS Developer Studio supports generation of all necessary files, use the
tool to create a model that generates all necessary files with accurate content.
For the Data Mart view the following applies:
This is of course handled in the model. If the model support incremental load, it will be expected that the source table end with _MVT
MVT_CREATED_DT of data type DATE
is defined in generated view file.The column that contains the timestamp for each created row.
ID. In the
data mart version the derived value will be present in the MVT table. Just make
sure that the unique column is selected as the first column in the view.DEFINE MV = CUSTOMER_ORDER_LINE_MVT
...
CREATE or REPLACE VIEW &VIEW AS
SELECT
id id,
...
reporting_date reporting_date,
mvt_created_dt mvt_created_dt
FROM &MV col
-- Standard security implementation
WHERE EXISTS ( SELECT 1
FROM user_allowed_site_pub
WHERE site = dim_site_id)
WITH READ ONLY; For the online view the following applies:
MVT_CREATED_DT of data type DATE
is defined in generated view file.Make sure to define it as SYSDATE, i.e. a column of DATE type.
ID. In the
online version this is (normally) a derived value represented by
concatenated key columns. Just make
sure that the unique column is selected as the first column in the viewCREATE OR REPLACE VIEW &VIEW AS
SELECT
col.order_no || '^' || col.line_no || '^' || col.rel_no || '^' || TO_CHAR(col.line_item_no) id,
...
TRUNC(NVL(col.real_ship_date, col.date_entered)) reporting_date,
SYSDATE mvt_created_dt
FROM &TAB col, &TAB_CO co
WHERE Bi_Utility_API.Bi_Access_Granted = 'TRUE'
AND col.order_no = co.order_no
-- Standard security implementation
AND EXISTS (SELECT 1
FROM user_allowed_site_pub
WHERE co.contract = site)
WITH READ ONLY;
Note: The online view will always contain a call to the
deterministic function Bi_Utility_API.Bi_Access_Granted that finds
out if access is granted. IFS Developer Studio will add this call
automatically.
Access view examples related to FACT_CUSTOMER_ORDER_LINE can be downloaded if needed.
Next step will be to validate the generated metadata file. The model handles
two attributes behind the scenes, attributes that are never supplied in the
model, i.e. the unique identifier and the created timestamp. In the metadata
file these attributes are added as
&FACT.MVT_CREATED_DT and &FACT.ID
A typical example of what the changes look like is taken from metadata for entity FACT_CUSTOMER_ORDER_LINE.
rec_.Fact_Item_Id := '&FACT..MVT_CREATED_DT'; rec_.Fact_Id := '&FACT'; rec_.Description := 'MVT Created Date'; rec_.Installation_Name := 'MVT Created Date'; rec_.Column_Name := 'MVT_CREATED_DT'; rec_.Data_Type := Xlr_Meta_Util_API.DATE_DATA_TYPE_; rec_.Nullable := TRUE; rec_.Is_Fact := FALSE; rec_.Display_In_Client := TRUE; rec_.Write_Back_Identity := NULL; rec_.Write_Back_Type := Xlr_Meta_Util_API.NO_WB_TYPE_; rec_.Zoom_In_Display_Item := FALSE; rec_.Drill_Down_Display_Item := FALSE; rec_.Supports_Zoom_In := FALSE; rec_.Supports_Drill_Down := FALSE; rec_.Drill_Down_Key := FALSE; rec_.Drill_Down_Source_Item_Id := NULL; rec_.Display_Order := NULL; rec_.Wb_Display_Order := NULL; rec_.Zoom_In_Display_Order := NULL; rec_.Drill_Down_Display_Order := NULL; rec_.Display_Folder := NULL; XLR_META_UTIL_API.Install_Fact_Item(rec_); -- unique key rec_.Fact_Item_Id := '&FACT..OBJID'; rec_.Fact_Id := '&FACT'; rec_.Description := 'Objid'; rec_.Installation_Name := 'Objid'; rec_.Column_Name := 'OBJID'; rec_.Data_Type := Xlr_Meta_Util_API.TEXT_DATA_TYPE_; rec_.Nullable := FALSE; rec_.Is_Fact := FALSE; rec_.Display_In_Client := FALSE; rec_.Write_Back_Identity := NULL; rec_.Write_Back_Type := Xlr_Meta_Util_API.NO_WB_TYPE_; rec_.Zoom_In_Display_Item := FALSE; rec_.Drill_Down_Display_Item := FALSE; rec_.Supports_Zoom_In := FALSE; rec_.Supports_Drill_Down := FALSE; rec_.Drill_Down_Key := FALSE; rec_.Drill_Down_Source_Item_Id := NULL; rec_.Display_Order := NULL; rec_.Wb_Display_Order := NULL; rec_.Zoom_In_Display_Order := NULL; rec_.Drill_Down_Display_Order := NULL; rec_.Display_Folder := NULL; XLR_META_UTIL_API.Install_Fact_Item(rec_);
Download the complete file MetaData_OrderBIFactCustomerOrderLine.ins if needed for more details.
Each entity supporting incremental load has its own metadata file. This file is also generated by IFS Developer Studio and it is named according to SnapshotMetaData_<component>BI<Entityclientname>.INS e.g. SnapshotMetaData_OrderBIFactCustomerOrderLine.INS
For more details about how to define the incremental specific metadata, please refer to Incremental Load Specific Metadata
Testing the implementation of Incremental Load is the last step before considering how to check in the files into the code repository.
Deployment of the files is easily done in IFS Developer Studio.
General checklist:
ROWVERSION
have been defined for source tables.If references are mode to tables in dynamic components, look up the CMV file and read the instructions how to test deployment and creation of dynamic CMVs.
ROWVERSION in source tablesTesting
Note: There is a risk that the initial load takes a long time. The needed time is dependent on number of transactions to transfer and on the Base view definition. The more complex the view is, the more time it will take. Testing this part also provides a reason for looking more deeper into the underlying entity definitions, i.e. trying to enhance the retrieval of data.
Note: The Data Mart view may contain security implementation that retrieves information with respect to current user
ROWVERSION of each table is updated (normally handled by the business
logic).
ROWVERSION column and also if there are other actions to be taken to
make the generated statements work more efficient.Note: If delete of rows in the snapshot table (MVT) is supported it can be worth testing to cases. The first is when the MVT table has a primary key, then make sure that the delete is performed using the primary key columns. The second case it to (temporarily) remove the primary key in the MVT table and deploy the metadata with id_column_name defined and then make sure that delete is performed using the identity column.
When testing the incremental framework it is important to make sure that everything works as expected. To find this out, the form Log - Incremental Load can be used. However by default the log is disabled. To enable it, open the Business Reporting & Analysis - System Parameters window and set the value for parameter Log incremental load actions to TRUE.
If Incremental Support is added to an existing Applications track:
But since it is an existing track the CRE files should not be added to the code repository. However the CRE files can be used as input to a CDB file that will create necessary MVT tables and CMVs.
Note: It is not allowed to add or modify CRE files in an Update or patch scenario.
If an existing entity, dimension or fact, supports Data Mart access via Materialized Views but the intention is to replace this access with an incrementally loaded source table, it is necessary to consider the upgrade or patch scenario, i.e. adding code to UPG or CDB files.
Xlr_Mv_Per_Refresh_Cat_API.Replace_Mv_In_All_Categories
Xlr_Mv_Util_API.Remove_Mv for all Materialized
Views that do not apply anymore.Note: In the Upgrade scenario, it is not allowed to add or modify CRE files
To support fresh installation of a component that in previous version used Materialized Views as the Data Mart source for one or more entities, it is important to make sure to remove these Materialized Views so they do not get installed.
A modification of an existing entity means that an incremental table will get one or more new columns or even that the expression for one or more columns differ from previous version. This leads to that all rows will get updated but there are different ways of handling this situation. If the entity has a complex MVB definition leading to that a full refresh takes a long time, then it could be worth just updating the MVT table and avoiding a complete refresh. If the entity is quickly refreshed then the MVT can be truncated.
Still all rows in the incremental (MVT) table will get an updated MVT_CREATED_DT which means that if IFS Analysis Models is used, all rows will get transferred next time the data warehouse is loaded.
Note: Important to read in order to understand how the incremental tables and views are built
The framework relies on the fact the it will always be possible to perform a statement like the following:
INSERT INTO <MVT table> SELECT * FROM <MVS view>
This might seem like a problem for doing patches or additions to an existing entity that support incremental load; is it necessary to make sure that columns are defined in a correct order will be the greatest worry.
But it is actually not as bad as it seems and this is why:
If the MVB view has columns that do not exist in the MVT table, then there is a risk that necessary information is not stored/handled. This case will lead to errors during validation.
If the MVT table has columns that do not exist in the MVB view, then there will be an error when the frameworks tries to create/rebuild the MVS view. This case will lead to errors during validation.
This means that the order of columns will
not be important, since the framework generated MVS view gets the columns
defined in the same order as the MVT, this the simple INSERT statement
exemplified above can be used.
If the snapshot metadata file is deployed then the MVS will get recreated.
If the MVB view is deployed the MVS view will also get recreated due to a call that is made in the apv file.
If none of these cases apply, make sure to recreate the MVS, e.g. in a CDB or UPG file.
BEGIN
Is_Mv_Util_API.Create_Mvs_View('&MVB');
COMMIT;
END;
The above block is the same as is used in the MVB file. The name of the MVB is the only needed input parameter.
If e.g. a new column has to be added to an entity that supports incremental load, i.e. modifying the MVT table, it must be decided how to perform this change.
The first case refers to an update/modification of an existing entity where a full refresh takes a long time (many hours). This applies to modifications made on an existing Applications track, i.e. a bug correction, or as an update of an existing entity on a new Applications release.
UPDATE statement.Since the MVT_CREATED_DT is updated the entity will automatically get fully transferred to the staging area in SQL Server if the entity is supported by IFS Analysis Models.
In a situation where the modifications are done to an entity that can easily be fully refreshed, the following is suggested:
For a scenario where a new entity is developed in a development project for a new Applications release:
If the MVB view is modified this means that the information in the view will change next time it is accessed.
To make sure that made changes updates the MVT table it is recommended to also define the entity as UNUSABLE, leading to a full refresh after the change.
An entity can programmatically be defined as having the status UNUSABLE. This is done by using the following PL method:
---------------------------------------------- -- Package Is_Mv_Util_API ---------------------------------------------- PROCEDURE Set_Unusable( entity_id_ IN VARCHAR2, fact_entity_ IN BOOLEAN);
The call will make sure that the status of the entity is defined as UNUSABLE but without changing the refresh status of referenced tables. This means that all referenced source tables may have the refresh status FRESH even if the entity is UNUSABLE. Since the entity was active before the call was made, the Activate option will not be enabled. The Refresh option will however be available and leads to a complete refresh.
The file <component>MvRefreshCategoryDetails.ins contains pre-defined Data Mart refresh categories.
It is necessary to make sure that this file is executed as the last INS file among the files in the BIServices folder. To handle this, make sure to add the file to the [CapMergeFilesLast] section in the deploy.ini file.
[CapMergeFilesLast] File1=ShopOrderSD.apy File2=ShpordInfoSourceDefaultFolder.ins File3=Insert.cre File4=ShpordMvRefreshCategoryDetails.ins
In the example above the SHPORD specific file ShpordMvRefreshCategoryDetails.ins has been added as the last file to the [CapMergeFilesLast] section. This means that it is executed after all other INS files, e.g. after all metadata related to incremental load. This is necessary in order to be able to address the snapshot (MVT) table in calls made in the refresh category file.
If Data Mart access is changed from a Materialized View to a incrementally loaded table as part of an upgrade to a new release of IFS Applications or as a part of a patch, it is is important to properly remove the obsolete Materialized View and replace it.
The suggested way is to create a POST installation file, e.g. POST_SHPORD_UpgRefreshMvCategories.sql.
Note: It is important to place this file in the ordinary database folder for the component, e.g. <component>\source\<component>\database. Do not place the file in the BIServices folder. The reason is because IFS Config Builder does not look for post files in sub folders.
SET SERVEROUTPUT ON
PROMPT Starting POST_SHPORD_UpgRefreshMvCategories.sql
-----------------------------------------------------------------------------
------------------- REPLACE ALL MV usages WITH MVT ------
-----------------------------------------------------------------------------
BEGIN
IF Database_SYS.Mtrl_View_Exist('SHOP_ORD_MV') THEN
Xlr_Mv_Per_Refresh_Cat_API.Replace_Mv_In_All_Categories('SHOP_ORD_MV' , 'SHOP_ORDER_MVT') ;
Database_SYS.Remove_All_Cons_And_Idx('SHOP_ORD_MV', TRUE);
Xlr_Mv_Util_API.Remove_Mv('SHOP_ORD_MV');
END IF;
IF Database_SYS.Mtrl_View_Exist('SHOP_ORDER_MATERIAL_MV') THEN
Xlr_Mv_Per_Refresh_Cat_API.Replace_Mv_In_All_Categories('SHOP_ORDER_MATERIAL_MV' , 'SHOP_ORDER_MATERIAL_MVT') ;
Database_SYS.Remove_All_Cons_And_Idx('SHOP_ORDER_MATERIAL_MV', TRUE);
Xlr_Mv_Util_API.Remove_Mv('SHOP_ORDER_MATERIAL_MV');
END IF;
END;
/
PROMPT Finished with POST_SHPORD_UpgRefreshMvCategories.sql
The example above shows the following actions:
Make sure to define the SQL file in the the [PostInstallationData] section in the deploy.ini file.
[PostInstallationData] File1=POST_SHPORD_MatAllocPositionPart.sql File2=ShpordTimman.ins File3=POST_SHPORD_RemoveRecvOpReport.sql File4=security_ShopFloorServices.ins File5=POST_SHPORD_ProjSOMatSupplyCode.sql File6=POST_Shpord_EstimatedCosts.sql File7=POST_Shpord_CreateCostDetails.sql File8=POST_SHPORD_RemoveActivityObjectConnection.sql File9=POST_SHPORD_DataCaptureRecShopOrd.sql File10=POST_SHPORD_DataCaptManIssueSo.sql File11=POST_SHPORD_DataCaptSOPickList.sql File12=POST_SHPORD_RemoveObsoleteReports.sql File13=POST_SHPORD_UpgRefreshMvCategories.sql
Above is an example from deploy.ini file of SHPORD component. The file POST_SHPORD_UpgRefreshMvCategories.sql has been added to the [PostInstallationData] section.
There are some special PL methods available related to the framework for incremental load. Please refer to the general section about useful PL methods.
If an entity supporting incremental load is dependent of a source table in a dynamic component, a component that might not be there at installation time, then the Materialized View that checks max rowversion/timestamp, the CMV, cannot be created directly. Instead the definition is stored in a table and will during the installation process be created if the dynamic component is available.
More than one entity can have a dependency to the same source table.
If an entity is changed so that there is no more any need for the dynamic source table, then it is necessary to remove the registered definition. This is done by using the method Is_Entity_Dynamic_Cmv_API.Remove_Cmv_Definition
One issue to be considered is if the Materialized View itself, the MV created by the registered definition, should be removed or not. To figure this out the following can be done:
SELECT * FROM IS_ENTITY_DYNAMIC_CMV_TAB WHERE SOURCE_TABLE='<source_table>'
If same name then the Materialized View should not be removed.
If different names are used, then the MV related to the entity investigated should most likely be removed.
BEGIN
Database_SYS.Remove_Materialized_View('<CMV_NAME>',TRUE);
END;
/