Performance Improvements¶
Fetching multiple values in Commands¶
Every call adds an overhead for the round trip to the server. Take time to revise your commands to minimize the number of server calls needed. Ultimately, you should strive for doing only one server call when you initialize an assistant or dialog. Rather than using set of functions to fetch values, whenever possible try to use a function that returns a structure containing multiple values.
Example: In the projection, define the function with structure.
structure PersonDetails {
attribute Name Text;
attribute Address Text;
attribute Region Text;
}
function GetPersonDetails Structure(PersonDetails) {
parameter PersonId Text;
}
Then in the client, you can access the attributes on the variable using the dot notation.
command GetPersonDetailsCmd {
variable DetailsStructure {
type = Structure(PersonDetails);
}
execute {
call GetPersonDetails(PersonId) into DetailsStructure;
set PersonName = DetailsStructure.Name;
set Address = DetailsStructure.Address;
set Region = DetailsStructure.Region;
}
}
Replacing Get methods and Prefetch using \$expand¶
Improve performance by removing usages of:
- Fetch attributes with Get methods
- Prefetch attributes, in the client.
Client syntax that can be used to get values into the client using references. This can be used instead of fetch attributes (use get methods) and prefetch attributes.
There are many projections where fetch attributes are created using API Get methods. Due to the performance related concerns about the usage of get methods such as the context switch between plsql and sql occur when using get methods which is a costly operation, it has been decided to use the odata feature called “$expand” to enable using references instead of fetch attributes that uses the get methods. In addition to replacing the get methods, same feature is proposed to use instead of the prefetch attributes that are created in the projection model. When you use fetch or prefetch, those attributes are created in the main entity which is unnecessary in many cases, but with the \$expand implementation it will not create more attributes in the main entity but use the reference with a special syntax in the client model to get the values from referenced entity.
Syntax that needs to be used in the client is as follows:
<ReferenceName>.<AttributeName>
e.g.
field CustomerRef.Name;
Get methods It is required to create a reference in the projection model:
reference PartNoRef(PartNo) to PartCatalog(PartNo);
Then it is possible to use it in the client model:
field PartNoRef.Description;
field PartNoRef.InfoText;
However, there can be scenarios where you cannot clearly define a reference like above, in that case it is fine to use the fetch attributes. But try to create references in all the possible places instead of using get methods.
Prefetch
It’s possible to get values using the reference (using above syntaxes) without adding new attributes to the main entity.
How does this work?
When the above syntax is used in the client model, odata \$expand feature is used to expand the referenced entity and return the values together with the main entityset as inline data in a single response.
Example-
If the reference name is “CustomerRef” which is created using CustOrdCustomer entity and referenced from CustomerOrder entity, the URL would be something like,
CustomerOrders?$expand=CustomerRef
Server response contains a structure like follows with inline data,
CustomerOrder - OrderNo - Objstate ….. - WantedDeliveryDate - CustomerRef (CustOrdCustomer) - Name - CurrencyCode - NoteId
Where can you use the syntax?
You can use the new syntax in the places where you use the regular attributes.
- fields and attributes used in components (Eg - Key of Person Widget)
- LOV description
- Commands
- Expressions/Conditions
- Labels etc.
Example -
entity CustomerOrder {
reference CustomerRef(CustomerNo) to CustOrdCustomer(CustomerNo)
}
list OrderList for CustomerOrder {
label = "Customer Orders List - ${CustomerRef.Name}";
field OrderNo;
field Objstate {
label = “Status”;
}
lov CustomerRef with CustomerSelector using Customers {
label = "Customer";
description = CustomerRef.Name;
}
field CustomerRef.Name {
label = "Customer Name";
}
field CustomerRef.CurrencyCode {
visible = [CustomerRef.CurrencyCode != null]
}
}
What is \$expand?
It is the OData way of reading inline (eager loading) data in a single response.
What you could do with it?
You can reduce the number of client to server calls, where you used to get the navigated information. In other words, client can get the inline data in a single server response.
Avoid Get methods when validating¶
instead use copy attributes option from referenced data sources.
In IEE it is a common scenario to use the validate event to fetch dependent values using Get method calls.
In IFS Marble language, instead of using Get method calls in validations, it is possible to use copy attributes option from referenced data sources.
Here the option to get information from another entity as an editable value on the entity which also can be saved to the server. The normal scenario is to use that value as a default value which the user can change and which will be sent to the server.
To make this happen the attribute must already exist on the entity in the projection, and this is because it must be part of the entity to be sent to the server.
Example:
attribute OppDescription Text;
reference BusinessOpportunityRef(RefId) to BusinessOpportunity(OpportunityNo) {
copy Description to OppDescription;
}
Here, when selecting Business Opportunity, it will set the Description to OppDescription field. The OppDescription field will also be set to dirty making it part of the data to be sent to the server when saving.
Use \$select functionality to get the data used by the Client¶
To achieve this, we use odata functionality \$select. This was implemented in the odata provider. When calling the entityset we use the \$select part in the URL with the used attributes in the page to get only the required data into the client.
Mainly we use \$select in the following places:
- For the main Entity
- For each reference
If you check the server call for the Entityset it will contain some \$select statements added to the main Entityset and references.
Example:
bring only the selected attributes:
CustomerOrders?$select=OrderNo,OrderType,CustomerNo,WantedDeliveryDate&$expand=CustomerRef($select=Name,Address),AgentRef($select=Name,ShopAddress)
As you might already have noticed, challenging part here is to identify the attributes that are used in the client. So, do you need to specify these select attributes in your client file?
No, you don’t need to do that. Developer studio and Client FW will take care of identifying all the attributes used by the Page/Element in all the possible ways and will add them into the appropriate \$select query option.
- Attributes used as fields and in other related elements (Contact Widget, Progress field, etc)
- Attributes used in labels, MarkdownText, etc in \${AttributeName} format
- Attributes used in expressions, emphasis and Commands
If you check the client metadata file (make sure you redeploy your local client files using latest version of Dev Studio) you can see a section called ‘selectAttributes’ for each element which contains a list of attributes used by the element.
There are some attributes we extract from the client side as well (Ex. - attributes used in override section of element, parent attributes used by the calendar, keys used when there is a binding, etc).
We also do a check from the client to make sure that attribute is available in the entity to avoid error responses that can occur because of having invalid attributes in \$select. If all the attributes in the entity are used, then we don’t add the \$select part related to that entity.
Bad performance when having arrays¶
PROBLEM
When you have TAB implementation in Aurena, we usually use Array implementation to populate data in the TAB. Because of that, at run time, it generates SQL join connecting parent and child array. If the array is based on complex view, resulting JOIN may be very expensive and that makes TAB population very slow.
SOLUTION
Instead of using Array implementation, lists in the TAB can be populated from a function. By adding parameters to function, result can be filtered from parent keys. In addition to that, it makes sure there will be no SQL JOINS happens and always generate single SELECT statement.
PROS AND CONS
The above given solution is ideal when the Array is based on a complex view (here are nested views with costly JOINS and PL/SQL methods calls).
If the List in the TAB is editable,“basedon” attribute should be set to get the full support for CRUD operations. If not following issues may exist.
when creating new records, no parent keys are copied to the new record, instead these have to be included in the copyoncruddefault - also it would not be possible to have any logic on the CRUD_Default based on the parent values as they are not currently being passed.
Different views for populate and LOV¶
PROBLEM
When having complex LOV views, page takes huge time to populate.
SOLUTIONS
Investigations revealed that the OUTER JOIN against complex LOV views takes long time for the population of the window, therefore we can use several alternative approaches to get the relevant values from Base view during the populate and use LOV view only when selecting the LOV field. Several solutions are listed below according to the preference.
SOLUTION 1 - (ENTITYSET APPROACH)
Step by step explanation
- Declare the reference in
.projectionagainst the Base view which you need to use for the populate - Declare
Entitysetin the projection for the complex view in LOV - Define your LOV field in the client using
entityset
PROS AND CONS
This is a simple implementation as developer only needs to add few lines. But If you need to filter LOV on bind values, this will not work. For such cases, Function approached which will be explained in next solution should be used.
Example :
Let's assume there is reference as below for a LOV and it is connected to complex view (ProjectAccessEmpNoPt). We comment that out and create new reference to simple base view which gives same information. Most of the situations, you may find simple base view as alternative. Now we know Outer Join created at population is simple.

In addition to that, entityset is also declared in the projection for LOV
entityset.ProjAccessEmpSet.for.ProjectAccessEmpNoPt;
In the client file, following change is done. LOV is written so that it can use the entityset created earlier
Before
lov.EmpNoRef.with.ReferenceProjectAccessEmpNoPtSelector.using.ValidEmpNo.
description = EmpNoRef.Name;
After
lov EmpNoRef with ReferenceProjectAccessEmpNoPtSelector using ProjAccessEmpSet{
description = EmpNoRef.Name;
If you need further filtering, WHERE condition can be added as follow. But you can’t do filtering based on bind values.

SOLUTION 2 - (FUNCTION APPROCH)
Step by step explanation
- Declare the reference in .projection against the Base view which you need to use for the populate
- Write a function with where statement to use the view which you need in LOV
- Define your LOV field with the reference selector using the function created
PROS AND CONS
The above given solution is good when you have complex LOV views. Further You might need to Override Reference selector to adjust number of columns displayed in LOV and Column labels. In scenarios where you have parameters to filter the LOV view, this approach needs to be evaluated.
Example :
Remove the complex reference and instead point to simple view
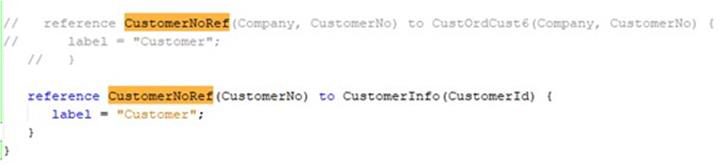
In the client, LOV is written using a function which creates actual LOV select and filtering

Function is created in the projection as follow
function CustomerNoLovFunction List<Entity(CustOrdCust6)>{
parameter Company Text;
--where = "Company =:Company";
where = "((:Company IS NOT NULL AND Company =:Company)OR(:Company IS NULL))"
}
Setting values in server instead of client in assistants¶
PROBLEM
In Assistants there can be requirements,
- To start the Assistant with some default values - method calls in
Initsection of the Assistant and setting field values in.clientfile - Update field values based on another field validation -Validation method is called from a field in client and set values of the other fields using the return values in the client
SOLUTION
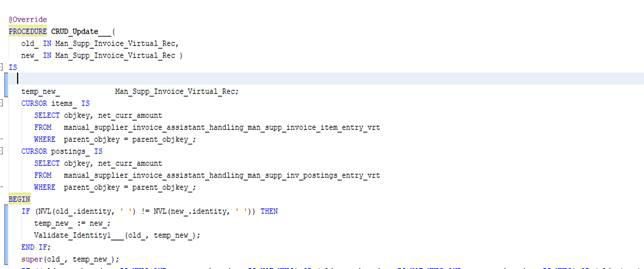
The same can be achieved by overriding CRUD_Create and CRUD_Update methods, then most of the work done in Server rather than in client. This will improve performance.
PROS AND CONS
Assistant savemode should be OnLostFocus to use CRUD_Update for setting values based on a validation method
Example

Here you can see lot of field values assigned based on ValidateIdentity method outcome
Instead of the client logic we can implement this in CRUD_Update method as follows: