Overview¶
Most business methods and processes are invoked from clients in direct response to client activities, but the system is also capable of executing jobs in the background, separated from user interactions. It is quite common that large, perhaps long-running tasks runs in the background. Depending on implementation, such background calls can execute either in the database tier or in the middle-tier. End users can submit such jobs for background execution, but jobs can also be scheduled to run at a later time or repeatedly.
Within IFS we distinguish 3 different types of Background Processing namely Background Jobs, Database Tasks and the Batch Processor. See below for more information about each of them.
Background Jobs¶
Executing methods in the application core tier is often performed in direct response to user activities. It is also common however, that larger jobs are submitted to be executed without any need for direct user interaction. The mechanisms utilized in the Application and provided by the Platform are described on this page.
Dbms_Scheduler¶
Oracle’s way of managing background jobs is to register them first as programs and then schedule them as jobs, through the system service dbms_scheduler. This Oracle feature is mainly known as the scheduler, so when we talk about the scheduler we refer to Oracle’s concept for background jobs. If setting the initialization parameter job_queue_processes to 10, then the database can start up till 10 SNP processes (if needed) that execute jobs scheduled in dbms_scheduler. IFS Applications uses the scheduler`to execute its own background jobs and scheduled tasks through the system servicesBatch_SYSandTransaction_SYS`.
Batch_SYS holds an API for submitting IFS Cloud driving processes into dbms_scheduler through New_Job.
Background Jobs¶
In IFS Cloud the concept for executing server methods in the background without any contact with the client, is simply called Background jobs. The reasons for running server methods in the background are many, for example the server job may take a long time to complete, the load and the things the job does may require executing in off-peak hours, and the user may want to do something else while the server job executes.
Transactions_SYS holds an API for submitting background jobs into Batch Queues through Deferred_Call.
Schedules¶
Schedules are a special type of background job. A new background job is submitted every time a schedule has passed its next execution date. This background job is executed like any other background job and ends up in the background job log. Schedules lets the server run the scheduled job after a predefined execution plan. To be able to schedule a task you must define a task or a chain in the schedule task repository. When the stop date is passed, a schedule is complete. If no stop date exists, the schedule will remain active forever, unless you manually deactivate it.
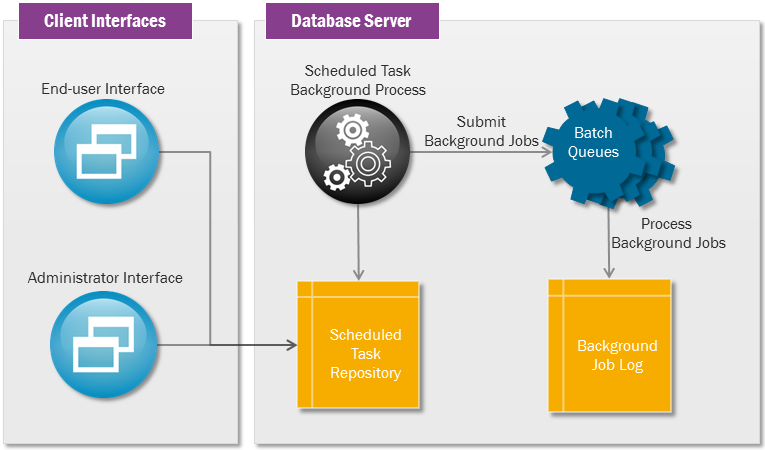
Batch_SYS holds an API for registering and scheduling Scheduled Tasks through Register_Batch_Schedule_Method, Register_Batch_Schedule_Chain and New_Batch_Schedule.
Schedules are divided into three groups:
- Scheduled Tasks
These are normal background jobs without any printed output - Scheduled Chains
This is one or more background jobs running in sequence, with a possibility to stop the chain if one step goes wrong. - Scheduled Reports
These are scheduled operational reports that produce report output
The relationship between the scheduler, background jobs and schedules¶
- The scheduler (Dbms_Scheduler) should be used for processes that drive IFS Cloud. An example of such a process is the Data Archiving process that checks for Data Archive Objects to file to the archive. It is only the framework that should create such processes.
- Background Jobs are intended to be executed once, as soon as possible, so that an end-user can do something else while the background job finishes.
- Schedules are intended to execute once or more at a specified time. End users can check the result of a schedule when the job has finished. When a schedule is executing it is considered to be instantiated as a background job.
Batch Queues¶
The main purpose of Batch Queues is to spread the job load, mainly between different Batch Queues which means between different scheduler processes.
When you initiate a Batch Queue, a job called Transaction_SYS.Process_All_Pending is submitted into the scheduler. This scheduler job executes all background jobs that match the criteria for the Background Queue.
When defining a Batch Queue, an execution plan has to be set up; that is specifying the number of processes, the language and if necessary, server methods to execute. The number of processes determines how many Batch Queue processes should be possible to start for the scheduler for this queue. The language is used to be able to execute language dependent background jobs in different queues. The method name is used to determine in which queue the submitted background job should be executed. If the method isn’t registered in any Batch Queue it will be registered in the Batch Queue chosen the first time it is executed.
Also remember that if you want jobs to be executed sequentially per Batch Queue you can't have more than one process per Batch Queue.
The parameter in Oracle Server (JOB_QUEUE_PROCESSES in Init.ora) must be increased to get full use of multithreaded batch queues, e.g. this Oracle parameter should not be lower than the total number of processes for all active queues in the system. Too many activated processes can use a great amount of server memory and processor resources.
The relation between the scheduler and JOB_QUEUE_PROCESSES is a bit hard to understand, you can read more about the relationship here.
Security¶
A user can only see the background jobs that the user has submitted, except users that have been granted System Privilege ADMINISTRATOR.
Only server methods granted to the user are available for the user to schedule as a task.
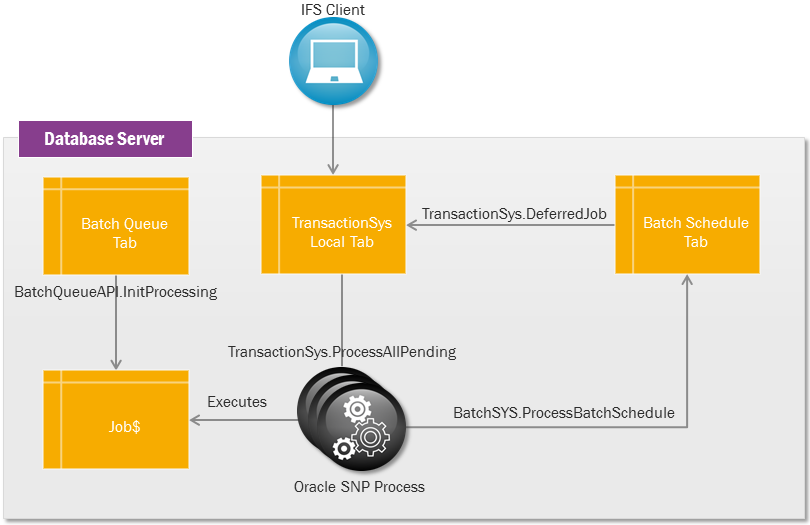
Schematic view of jobs and queues
Oracle SNP Processes were originally created for replication purposes and SNP stands for Snapshot. SNP processes are used more in a general sense today.
Database Tasks¶
The execution of a database stored procedure can be scheduled as a task which executes once or several times according to a predefined schedule. Multiple such tasks can be configured to execute in a "chain" of tasks executed in a specified sequence. A Scheduled Tasks background process regularly checks for scheduled tasks or chains of tasks to execute. When the Scheduled Tasks process finds a task or chain to execute, it submits it as a database background job. This background job is executed as the user who scheduled the task.
Batch Processor¶
General¶
Batch Processor is a part of IFS Connect framework responsible for background processing of Application Messages.
The process can involve both synchronous calls and background processing of messages.
Batch Processor is based on Oracle Database Pipe concept using PL/SQL package DBMS_PIPE invoked from a database trigger in combination with JMS messaging and a dedicated Message Driven Bean in the application server deployed as a part of ifsapp-int.ear JEE application. In addition to these J2EE Timers are also used to read the application messages effeciently.
Note: Please note that if upgrading from IFS Applications 8 (or earlier) the old Batch Server needs to be stopped and removed. Read more about Removing Batch Server.
JMS Message Flow¶
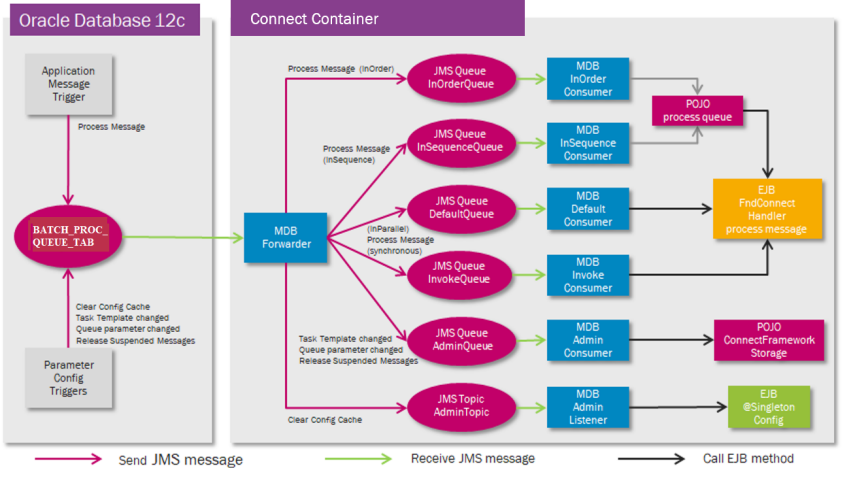
Whenever a new Application Message is created with state ‘Released’ or state of an existing massage has been changed to 'Released', a JMS message containing the ApplicationMessageId of the created/modified application message is posted by a database trigger on BATCH_PROC_QUEUE_TAB. For In-Parallel message the trigger changes also state of the message to 'Processing'.
Database triggers on configuration tables also post JMS messages to the same table signaling configuration changes.
A Message Driven Bean (Forwarder MDB) subscribing to this JMS queue is processing messages posted on this queue. Depending on the type of received message the Forwarder MDB is forwarding the JMS message to another JMS queue or topic. Processing of single Application Message is performed by the Message Processor, which is called through an EJB, FndConnectHandler, in a separate transaction.
Purpose of JMS queues and topics:
- DefaultQueue
Used for asynchronous Application Messages posted to an In-Parallel Message Queue. A JMS message on this JMS queue will trig processing of the given Application Message. - InvokeQueue
Available as of patch 145612 (Update 5). Used for synchronous invocations from PLSQL Access Provider. Application Messages are always posted to theDEFAULTMessage Queue. - InOrderQueue
Used for asynchronous Application Messages posted to an In-Order Message Queue. A JMS message on this JMS queue will start processing of all Application Messages from the given Message Queue. Application Messages will be processed according the Application Message ID and the Message Queue will be stopped on failure. - InSequenceQueue
Used for asynchronous Application Messages posted to an In-Sequence Message Queue. A JMS message on this JMS queue will start processing of all Application Messages from the given Message Queue. - AdminQueue
Used for administrative purpose by database triggers on configuration tables. - AdminTopic
Used for administrative purpose by database triggers on configuration tables. Trigs clearing of configuration cache and synchronization of Connect Readers.
Note: Behavior of all MDBs (Message Driven Beans) can be controlled by Work Managers.
Restricted Messages¶
The JMS flow for In-Order and In-Sequence messages is slightly different. The database trigger doesn't change the state leaving the Application Message in state 'Released'. The JMS message sent by the trigger contains also the Message Queue name, so Batch Processor knows the type of the queue. If the queue is an In-Order queue then the Batch Processor will execute all application messages in state 'Released' posted to this Message Queue in a loop sorted by ApplicationMessageId. For In-Sequence messages Batch Processor will process up to a number of messages defined by the THREAD_COUNT parameter at time, but any particular order is not guaranteed (read more about how to Configure Message Queues).
Once a single message is picked up for execution, it's state is changed to 'Processing'. The message is then saved before calling Message Processor.
Note: A failed message (in state 'Failed') in an In-Order queue will automatically stop the queue. If the message processing is finished with state 'Waiting', the Batch Processor will not stop the queue, but will not continue with other messages until the current one is finally processed, i.e. in state 'Finished' or 'Failed'.
Note: If message processing in an In-Sequence queue is finished with state 'Waiting', the Message Processor will create one-time scheduled task for this message and continue with the next one. The postponed message will be processed by Batch Processor again later on according to values of
MAX_RETRIESandRETRY_INTERVALparameters on the actual Connect Sender.
Scheduled Tasks¶
A scheduled task is controlled by a database scheduler. A scheduled task in the database will periodically change the state of corresponding Application Message from ‘Waiting’ to 'Released' according to the specified agenda. It will also set state of address lines to ‘Released’ and remove reply message bodies.
The scheduled task knows if there will be more iterations or not and sets the Application Message attribute NextState to ‘Finished’ or ‘Waiting’ depending on this information. It will also set the next execution time, if any, on the message. This information is important if any of the address lines ends up in state ‘Retry’ - a “one-time” scheduled task, as described in the Application Message Flow section, will only be created if it will start before the next execution time according to the schedule scheme.
An ordinary scheduled task will change state of all address lines to ‘Released’, while a one-time task will change state of only those address lines that are in state ‘Retry’.
If the message execution fails, the final state will be set to ‘Failed’ anyway - it can be caused by an un-repairable failure, e.g. configuration error, and will require investigation. Consequently the background job will be stopped.
Database Triggers¶
Following triggers are defined in the database as a part of Batch Processor solution:
| Trigger | Database Table | Description |
|---|---|---|
| Application_Message_Jms_TR | FNDCN_APPLICATION_MESSAGE_TAB | Sends a JMS message if message state is Released Changes message state to Processing(for In-Parallel) |
| Print_Job_TR | PRINT_JOB_TAB | Creates new Application Message using Task Template |
| Config_Parameter_Detail_Jms_TR | FNDCN_CONFIG_PARAM_DET_TAB | Changed Task Template Releases jobs/messages (JMS message) |
| Config_Parameter_Jms_TR | FNDCN_CONFIG_PARAM_TAB | Clears configuration cache (JMS message) Stops/restarts queues (JMS message) |
| Config_Param_Distinct_Jms_TR | CONFIG_PARAM_DISTINCT_JMS_TAB | Limit duplicated JMS messages |