Analysis Models - Data Load Definition and Volume Configuration¶
This page provides information related to Analysis Models and how to create a Data Load Definition to be used to transfer data of one or many Tabular Data Sources from IFS Cloud database to the target database in SQL Server.
The individual data sources in the Load Definition can be configured with respect to data volume.
Also learn how to run a Data Load Definition and how to check the execution status.
General¶
A Data Load Definition is a definition of one or many Tabular Data Sources. Each source in the definition can be configured independently. A typical configuration is to specify the Load Type to be used for a source, e.g. if the source should be loaded Fully, Conditionally or Incrementally.
A Data Load Definition can either be generated or defined manually.
Once the definition is ready, a Load Run can be ordered, either directly or as a scheduled job. The run will start a job in the SQL Server database that runs an SSIS package that will execute each source in parallel. A Tabular Data Source has information about the source in the Oracle database and about the target in the SQL Server database.
A Tabular Data Source can also be defined such that the source is a view in the SQL Server database and the target is a table in the same database. This type of source is dependent on other sources and should normally be executed last to make sure that dependencies are handled correctly. The framework can automatically find dependency sources and make sure that they are executed during the last part of the transfer process.
Prerequisites¶
Before a Data Load Definition is created and executed, make sure that:
- The SQL Server host has been set up properly and that necessary users have been defined with needed privileges.
Find more information in the installation section. - The environment parameters have been set up properly and the framework environment in SQL Server has been set up succesfully.
Find more information in the installation section. - Make sure that all data base objects related to the data sources that are required by the Tabular Models to be used, have been created properly before running or scheduling a load run.
Read more information about DW object deployment.
Load Types¶
There are three possible load types:
- Full
- Conditional
- Incremental
The Load Type only applies to the transfer from the Oracle database to the target SQL Server database. The Tabular Data Source thus must have an Oracle source view and a target SQL Server table defined. If the Tabular Data Source only defines a source in the SQL Server database, the Load Type has no meaning.
Load Type - Full¶
This is the default Load Type for all Tabular Data Sources.
When reading data from the defined Oracle view to the target SQL Server table, all available data will be transferred each time a data load is executed. The Truncate SQL Table option will always be Yes, meaning that the target table will always be truncated before loading the table with new data.
Load Type = Full is typically used for Dimension related data transfer, since there are no standard Dimensions that support incremental load. To apply conditional load will, for most Dimensions, be very difficult. Other sources where Full load will take place are those representing additional help sources or data configurations.
Load Type - Conditional¶
Load Type = Conditional makes it possible to load data using a filter or WHERE condition, thus controlling the data volume.
Conditional load is more or less only useful for Fact related sources, since these sources represent transactional sources that can be of interest to load with less volumes than compared to a Full load. Fact sources normally also have columns that are appropriate to use in a conditional filter, e.g. a year, a date, a status etc.
For Dimensions, it is rather difficult to set up a conditional filter and still be able to load compatible data into the target database; if dimensional data is limited there is a big risk that the Fact sources have transactions the refer to non-transferred dimensional data.
If for a Tabular Data Source, the Load Type is set to Conditional and a Conditional Where is defined, then conditional load and the specific condition will be suggested by default when a Data Load Definition is generated that contains the data source.
Example 1¶
An Information Source contains large amounts of data spread over many years. There is no support for incremental load and a complete/full load takes too long time. The customer does not need to have more than the last three years of data. By adding a Conditional filter the time to transfer the needed data will be reduced. The Fact source has a column named CREATED_DATE which represents the timestamp when a transaction was created.
For this case the following is defined:
- Load Type - Conditional
- Where Condition
- EXTRACT(YEAR FROM CREATED_DATE) >= EXTRACT(YEAR FROM SYSDATE) - 2 - Truncate SQL Table - Yes
The defined volume configurations mean that everytime the definition is executed, the target table will first be truncated, then source data will be fetched using the defined condition as a WHERE expression.
Note that the Where Condition should never start with WHERE!
Example 2¶
Initialization of the data layer in SQL Server.
The involved Information Sources support incremental load, i.e. applies to the Fact sources only. The Information Sources also contain large amounts of data and there is a need to have all data available in the the database in SQL Server. A full transfer is needed before the incremental load can be initiated. Performing a full transfer of the involved large sources will be time consuming and the customer wants to avoid having to wait too long before being able to process the Tabular Models and start using them.
What can be done now is the following:
- Create a Data Load Definition only for the Fact sources.
- Configure the Data Load Definition such that only the current year is taken into account. This is done for all involved Fact sources. It has been figured out that transferring one year at a time would be a good approach and would be ready during one day.
- Load Type - Conditional
- Where Condition -
EXTRACT(YEAR FROM CREATED_DATE) = 2020 - Truncate SQL Table - No
- When the definition is executed only the selected Fact sources are handled. Data will be loaded conditionally and without truncating the target table.
- Once the transfer is ready, another Data Load Definition, referred to as complete load definition, is created that contains all necessary sources. In this definition the Fact sources are loaded using Load Type = Incremental. When this definition is executed, all dimensions and other help sources are loaded fully and the Facts are loaded incrementally.When ready it will be possible to process the required Tabular models.
- Now the next large Fact transfer is planned. The thing to do is to use the initially created fact-only Data Load Definition and to modify the filter to only consider previous year, e.g. Where Condition
EXTRACT(YEAR FROM CREATED_DATE) = 2019. An appropriate day and time to start the load run needs to be planned. When this load is executed, only Fact sources are affected and only data for year 2019 will be considered. Note here the importance of having the Truncate SQL Table set to No so that loaded data is appended to the existing data. - The complete load definition covering all sources can now be executed again on a daily basis until the next Fact-only load is performed for the next year, e.g year=2018.
- The same procedure is followed until all Facts has been loaded with all needed years. After this point only the complete load definition is needed, since it loads the Facts incrementally and all other sources fully.
False Incremental Load¶
The Conditional load can also be used for a case called False Incremental Load.
For a Fact source, supporting true incremental load or not, it can still be possible to define a data load that simulates an incremental load but it will only be based on a filter definition that is a guess. For most Fact sources, the source view defintion is so complex that it, in general, is not possible to find a condition that correctly will select only new/modified transactions.
Assume that a full load has to be done first. The full load takes too long to run, so there is a need to reduce the load time. Now, if it is possible to define a filter condition that filters out a smaller portion of transactions without missing any transactions, the conditional load can be a possible option. If e.g. we know that only new Fact transactions are created, no modifications or delete are allowed, then it can be possible to set a condition where only transactions from e.g. two days back are handled. For this case we set the following:
- Load Type - Conditional
- Where Condition -
CREATED_DATE >= TRUNC(SYSDATE) - 2 - Truncate SQL Table - No
The following will happen:
- Transactions matching the Where Condition will be fetched
- All transactions in the target table that fulfills the Where Condition will be deleted.
- Fetched transactions will be inserted into the target table.
Load Type - Incremental¶
The Incremental load can only be used for sources that support true incremental loading. This means that the Facts/Dimensions must be supported by the incremental load framework in IFS Cloud. Currently approximately 50% of the Facts support this framework. No Dimensions are supported.
Read more about incremental load.
In short, the incremental framework makes sure that a source specific incremental table is updated in the IFS Cloud database on a regular basis. This table serves as a Data Mart source and it will contain a timestamp for each row that can be used when performing an incremental load from that table to the target table in SQL Server.
The WHERE condition is predefined and cannot be modified. This is because information about filter column can be retrieved from the incremental framework for each source and the latest used timestamp for incremental load to the SQL Server table can also be retrieved. When Load Type=Incremental is selected, the following statement will be defined:
MVT_CREATED_DT > '#LAST_MAX_INCR_LOAD_DT#'
It is strongly recommended to make sure that for sources (currently only Facts) that support incremental load, the used Data Load Definition is configured to use incremental load also for transfer to the database in SQL Server. Using true incremental load provides the fastest possible option to transfer needed transactions from the Oracle to the SQL Server database.
If, for some reason, the default incremental condition has not managed to transfer the necessary transactions, a simple work-around can be to modify do a manual change of the last registered timestamp for the Tabular Data Source, i.e. by setting it 1-2 days back in time.
Creating a Data Load Definition¶
Use this section to learn how to generate a Data Load Definition based on a specific Tabular model or how to create it manually.
Generating a Load Definition for a Tabular Model
Start on Tabular Models page, select a model and go to the detail page.
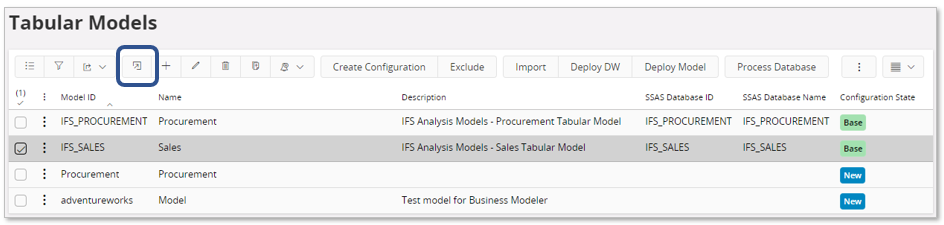
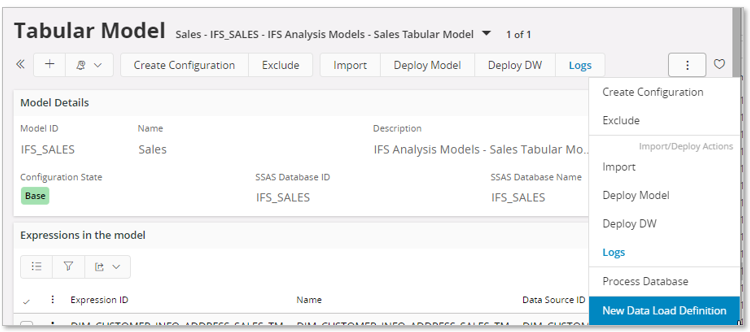
Use the command New Data Load Definition.
In the dialog provide a Data Load Definition ID and press OK.
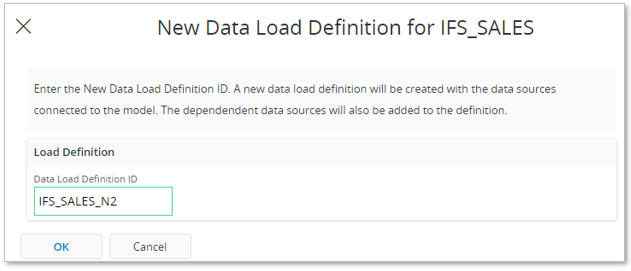
The Data Load Definitions page will appear.
Select the Data Load Definition ID and go to details, i.e. to the Data Load Configurations page.
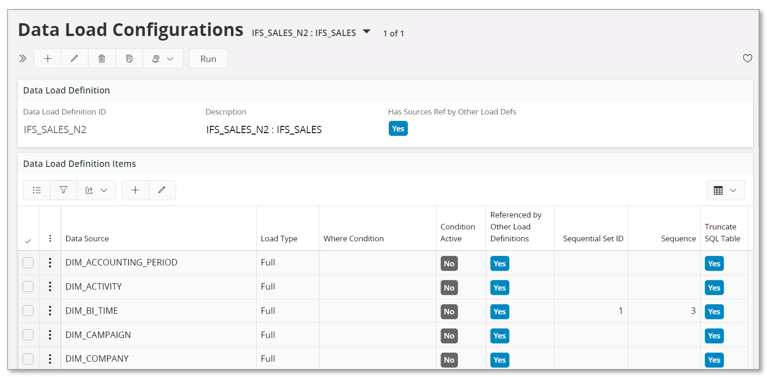
On this page, each Data Source can be configured, i.e. Load Type to be used, if the load should consider a Where Condition to reduce/specify the volume and if truncation should be done or not. A Where Condition can only be supplied when Load Type is Conditional. If a condition is defined and then the Load Type is changes to e.g. Full, then the condition will still be there but not accessible and the Condition Active will switch from Yes to N o.
Also note the two columns Sequential Set ID and Sequence. A sequential set is a group of data sources that should be executed as a group where the Sequence defines the order of execution within the set/group. This is typically needed for data sources that are dependent on other sources, i.e. data for the dependent sources must have been transferred first. For generated definitions the set information is created automatically.
Also note that there is a badge in the Data Load Definitions group that indicated if the load definitions includes data sources that are referenced by other load definitions. For each listed data source there is another badge that indicates if that particular source is also included in another load definition.
Creating a Load Definition Manually
Use the Data Load Definitions page.
Create a new data load definition.
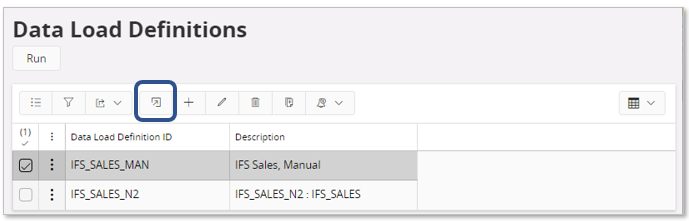
Go to details, the Data Load Configurations page and start selecting the data sources to be part of the definition and also configure each data source with respect to Load Type, Where Condition and Truncate SQL Table.
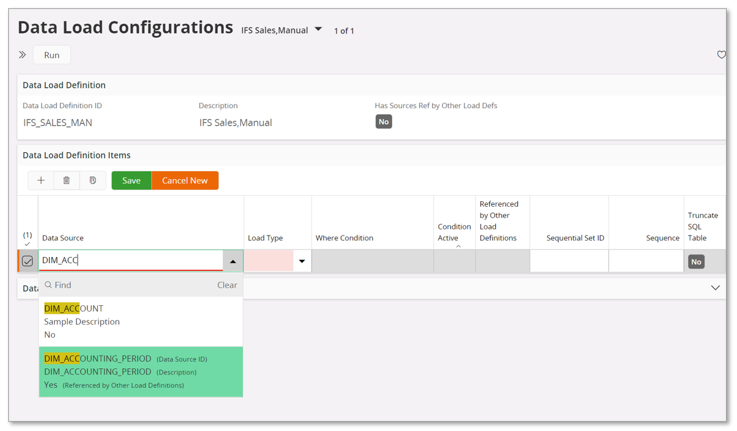
Using a manually defined Data Load Definition can be an option if there is one or few Tabular Data Sources that needs to be transferred as quickly as possible instead of waiting for the daily scheduled load runs. This type of definition is is probably never scheduled, rather executed directly after having completed the definition.
For a manual load definition it is important to make sure that all dependent Tabular Data Sources are also considered. Look up the initially selected sources, ínvestigate if there are dependent sources and if so, add them as well. When there are dependencies between sources the Sequential Set ID and Sequence need to be set properly. An option is to first create a load definition based on a model and use the generated info as input on how to set the load details.
Things to Consider
It is important to plan how to handle loading of the SQL Server database.
If the Information Sources used by a Tabular Model contain large amounts of data, it is probably an idea trying to do conditional load of transactions from the current year first and then load data from all other non-large-transactional sources as dimensions and data (filter) configurations. Once all sources have been transferred the Tabular Model can be processed. Next step will be to load more data for large Fact sources, i.e. to consider one more year. For more details, refer to Load Type - Conditional.
For Information Sources that support incremental load, i.e. applies to the Facts, recurring load should always be made using incremental data mart load. Please refer to Example 2, Load Type - Conditional and Load Type - Incremental.
Always make sure that all dependent Tabular Data Sources are considered.
If the load is expected to take long time, always define a scheduled execution.
Running a Data Load Definition¶
Before running a Data Load Definition make sure that each Tabular Data Source in the definition has been configured properly, i.e. with respect to load type and load conditions.
Assuming that we have generated a Data Load Definition with identity IFS_SALES_N2 based on the IFS_SALES model.
Next the details, the Data Load Configurations, have been checked and modified if needed.
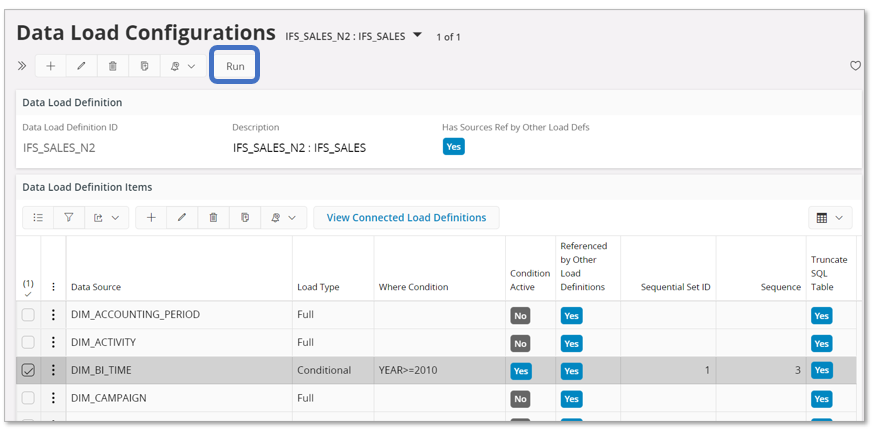
Execution can now be made in two ways, immediate or scheduled.
Immediate Execution¶
Collapse the Data Load Definition Items group.
Use the Run command to open the Tabular Model Load Run assistant.
Check that the Data Load Item List is ok and Finish the assistant to start an immediate execution.
In the Data Load Runs will get a new entry. Select it and go to the details page.
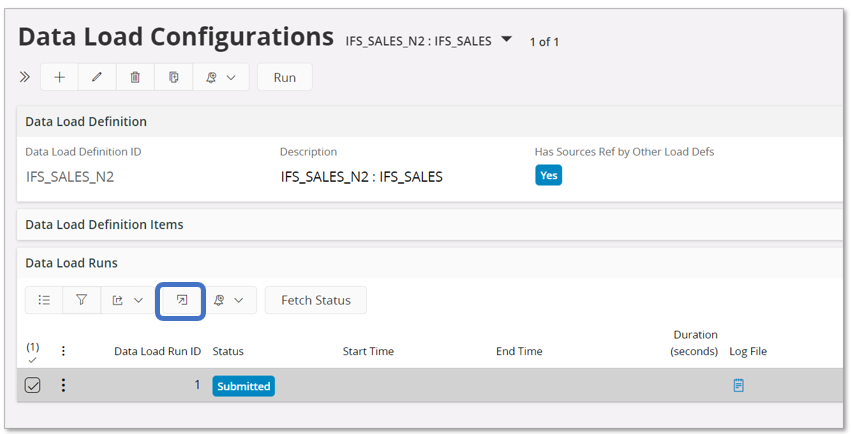
The Data Load Runs page will open.
Use the Fetch Status command button to fetch the current status of the execution.
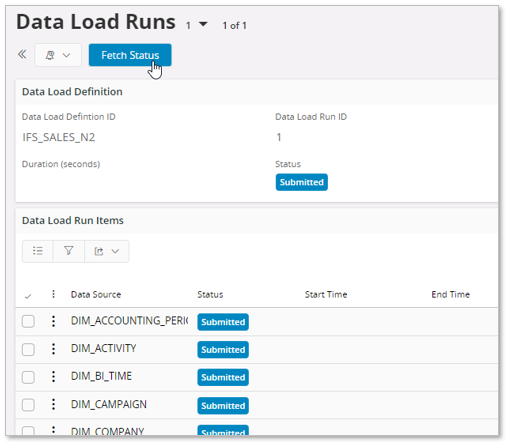
In this case we find that the execution has errors.
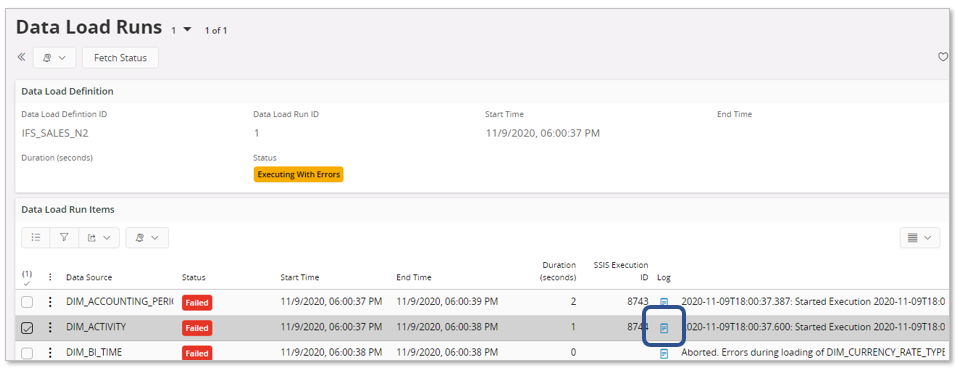
Each row has a Log column that will contain some information about what was about to be executed and reported error.
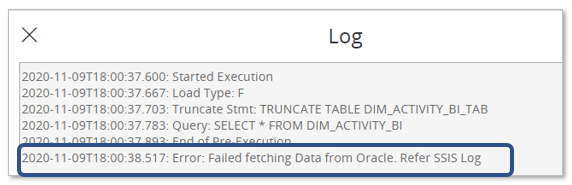
The log information directs us to the SSIS Log.
The Tabular Models framework support a couple of different logs, There logs explained more in detail in Analysis Models - Logs.
For now, only the fetched content in the SSIS Event Logs page is shown. The page contains several messages about failed tasks and a task typically has a detail that informs that fetching the data from the Oracle database is the problem.
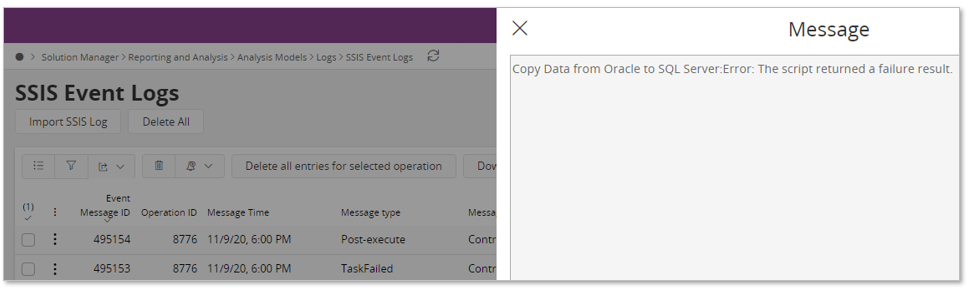
There is also another log we can investigate, supported by the SSIS Custom Event Logs page.

In this log we get a bit more detailed message. It was not possible to fetch the data due to that the database details according to the settings are probably wrong since it is not possible to connect to Oracle.
Now, the environment variables are checked and a minor error is found in parameters holding the Oracle database user name. After correcting the parameter, the environment needs to be refreshed. Since only the Oracle user parameter was affected, the Setup Environment assistant can be executed and all steps up to configuration of the SSIS Catalog can be skipped since it is only the SSIS configuration that needs to be updated.
A new execution if the load definition is now started.
Select the new Submitted row in the Data Load Runs group and go to details.
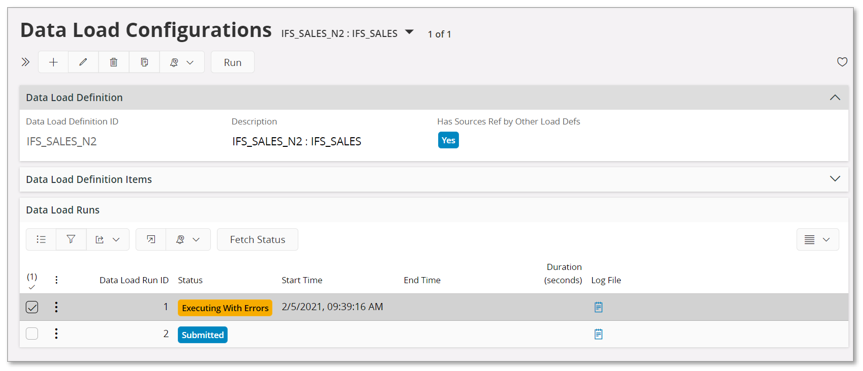
Use the Fetch Status command to fetch the latest status for the execution.
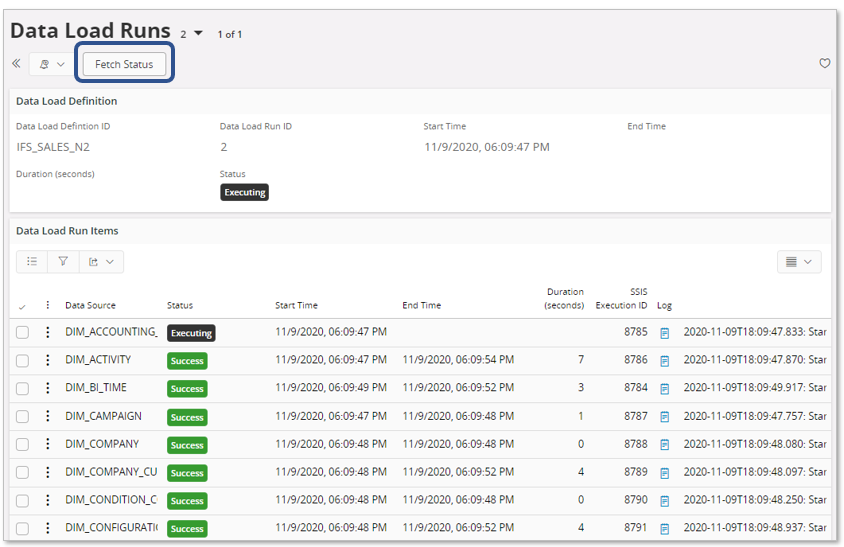
The main status is still Executing and looking at the details there are some sources that are not yet ready.
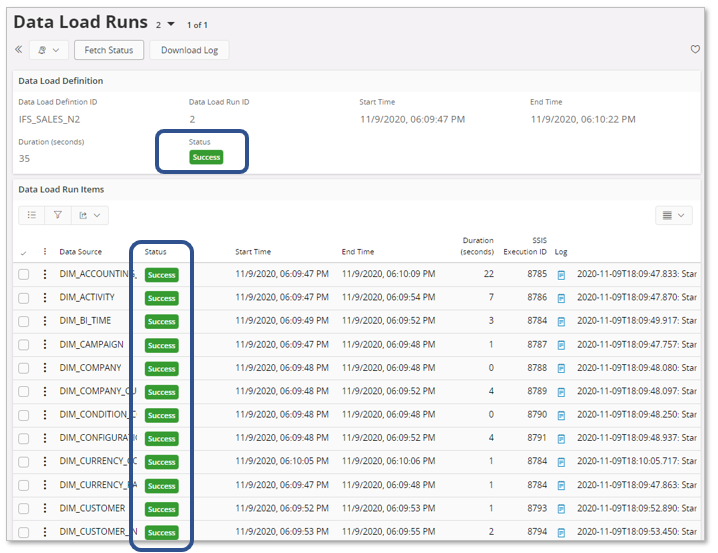
The execution ends with status Success on load run level, meaning that all individual sources have also completed with success.
Scheduled Execution¶
A Data Load Run can also be scheduled. This is the main refresh execution option in practical scenarios.
Note: Scheduling of a Data Load Run requires that the executing user has access to all necessary functionality. It will be necessary to make sure that special Routing Rules and Routing Addresses are available in IFS Connect. For more information see Remarks - Functionality Access.
Start the New Database Task Schedule assistant.
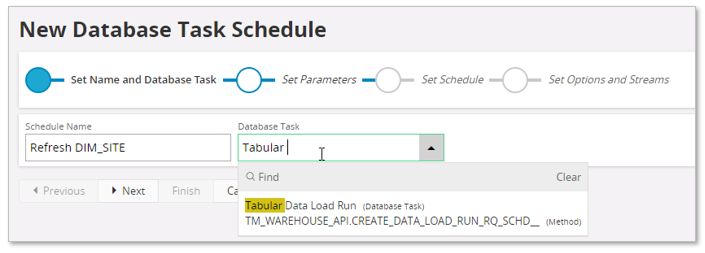
Provide an easily recognized Schedule Name and then lookup the Database Task named Tabular Data Load Run.
Go to Next step.
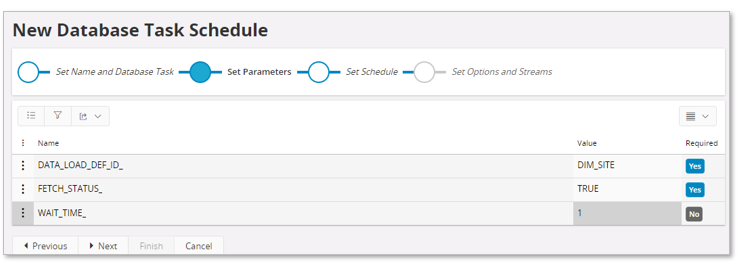
Provide parameters:
- DATA_LOAD_DEF_ID_
Identity of Data Load Definition to be scheduled - FETCH_STATUS_
Specifies if status should be fetched during the execution. Suggested to set TRUE. - WAIT_TIME_
Number of minutes between every status refresh. Default is 1 minut and in most cases the value does not have to modified.
Also note that there is another wait parameter involved, defined as part of the environment setup. The global parameter defines for how long time the status fetch should continue to be triggered every WAIT_TIME_ minute. Thus, if the environment parameter is set to 30 minutes and WAIT_TIME_ is set to 1 minute, it means that a status fetch will be made every minute but no longer than for 30 minutes. If the execution takes more than 30 minutes, the status fetch ends after 30 and then it will be necessary to manually fetch the status in the Data Load Runs page.
Go to Next step.
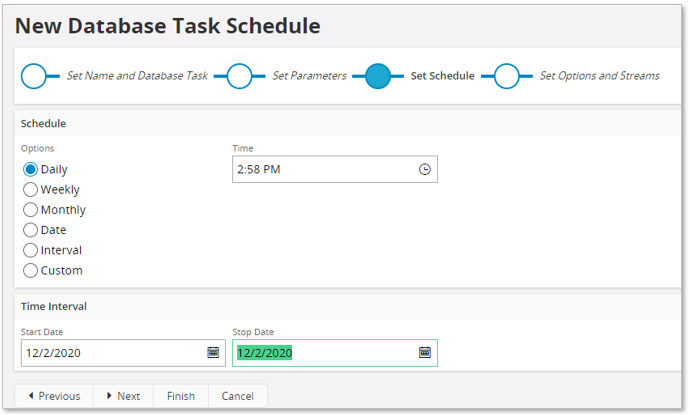
Provide scheduling options/info.
The last step can normally be skipped. Use Finish to create the schedule and open up the Database Task Schedule page.
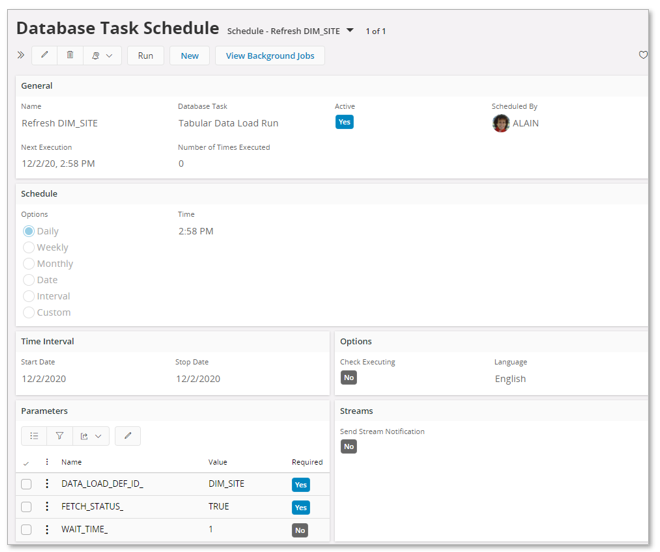
From the page, it is possible to navigate to the associated background job to get more information about the execution status.
Initially the background job will be in state Posted and is set to Ready when a successful execution has taken place.


Note: Currently the Status of the background job does not show when the complete data load is ready. Posted indicates when the job has been posted to the queue and Ready indicates that the job execution has been successfully handed over to IFS Connect.
Once the job has finalized, the status and details of the load run and its details can be found in the Data Load Runs page, i.e. the same way as when running a data load manually.
The status of the IFS Connect execution can be found by looking up the Message Function named IFS_TABULAR_MODEL_SERVER_INVOKE_HANDLING and then view details.
Remarks - Functionality Access¶
The user that handles scheduling of load configurations related to Tabular Models, needs to be granted a permission set that gives access to the scheduling functionality but also to functionality that is used when executing a schedule such as e.g. IFS Connect. The built-in permission set FND_ADMIN has the needed privileges.
This means access to:
- Scheduled Tasks
- Background Jobs
- Application Messages
- Routing Rules (IFS Connect)
Specific Tabular Models routing rules:- IFS Tabular Model Server Invoke Handling
- IFS Tabular Model Fetch Status Handling
- Routing Addresses (IFS Connect)
Specific Tabular Models routing addresses:- IFS Tabular Model Server Invoke Handling
- IFS Tabular Model Fetch Status Handling