Data Archive Objects¶
Data archive objects are intended for transactional business objects like customer orders, financial transactions or invoices, that the system can still work without. Data archive objects are not intended for system data like accounts, customers or products. There are some business objects that are between transactional business objects and system data like product structures, organizational hierarchy or sales parts. Data archive objects can be defined for these objects, but it will be of great importance that these objects have some kind of status attribute that shows that they are not in use anymore.
When defining a data archive object it is important that you keep the definition to one business object. For example: if you want to archive a customer and all of its corresponding customer orders, you must do this as two data archiving objects, customer and customer orders. It’s not suitable to archive this in the same data archive object because it becomes too complex.
Before archiving the data archive objects that you have defined you must be sure of that all areas of IFS Cloud have finished using the object. It’s also of great importance that all statistics (updates and reports), transformation to data warehouse objects (IAL and cubes) and so on have been done.
A data archive object is a definition of one ore more database tables in a tree structure. The tree structure starts with the parent table called the master table. The master table is the driver for the whole data archiving process. You define a where clause for the master table and the data archiving process fetches each master record that fulfills the where clause. For each master the whole tree structure of tables is processed. For each table you can decide what you shall do with the data.
Data Archive Source¶
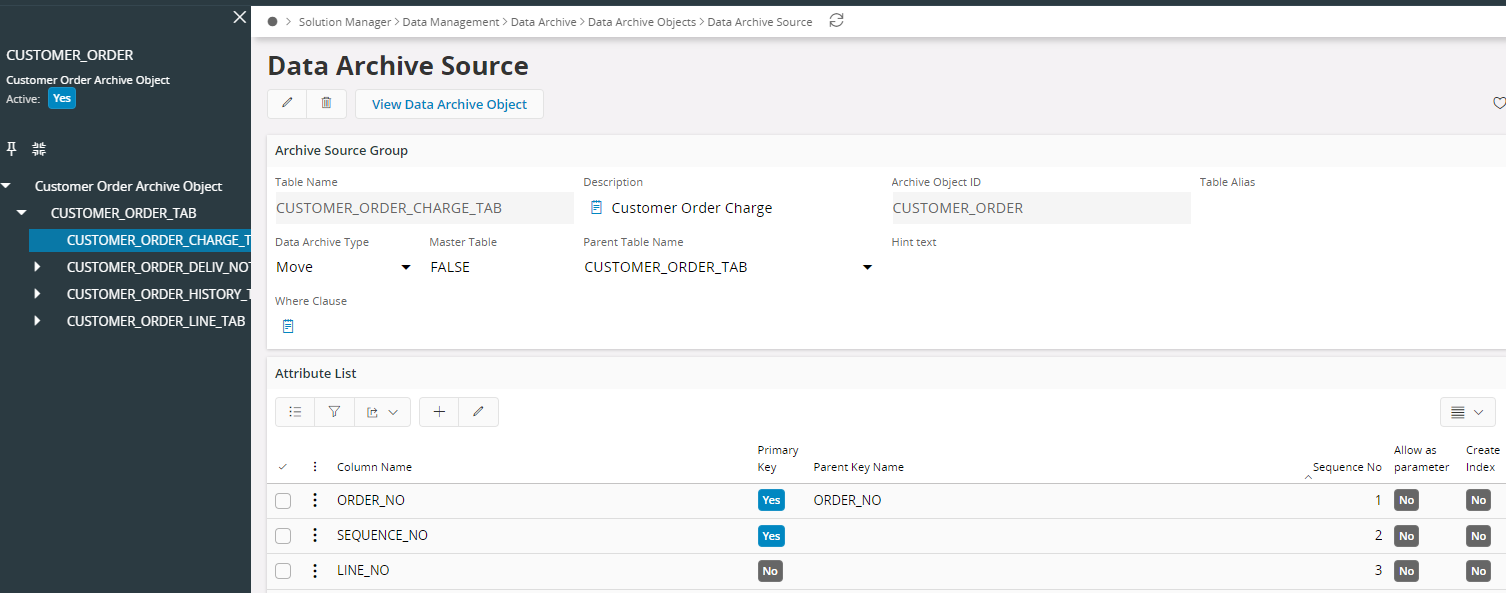
For the master table, it is possible to define which columns that can be used as parameters by the archive executions. Columns used, as parameters are probably scope columns like Company or Site, but can be other parameters like date or time parameters. Restrictions on the master tables where-clause are probably state or status columns.
| Column | Description |
|---|---|
| Table name | Name of the table included in the data archive object. |
| Description | Description of the table. |
| Archive Object Id | Data archive object id. |
| Table alias | A table alias can be set for the master table. The table alias can be used in sub-queries in the where clause. |
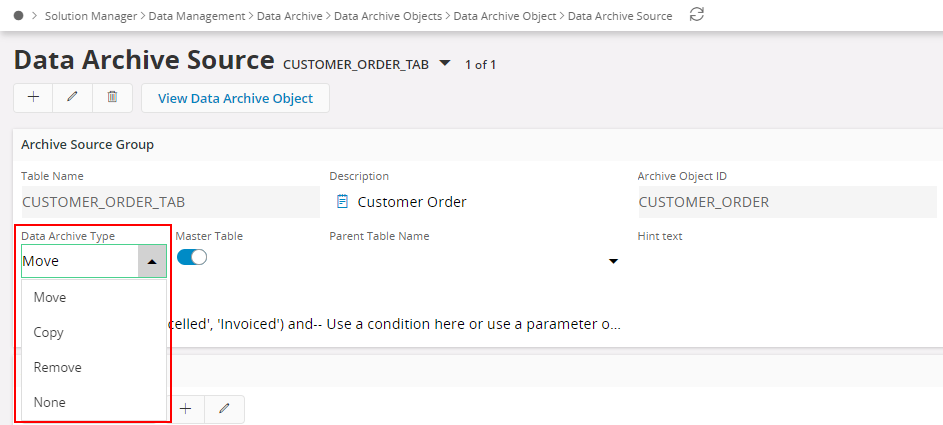
| Data archive Type | The data archive type decides how the data for this table is handled in the data archive process. The data archive type can have the values Move, Copy, Remove and None. For more information >> |
| Master table | Set to TRUE if the table is the master table. There can and must exist only one master table per data archive object. The first table in the data archive object must be the master table. |
| Parent table name | If the table is the master table then this field must be empty otherwise this field should point to the parent table. |
| Hint text | If the table is a master table you can write a hint text used in the select statement that fetches all master records. The hint should only be used when trying to improve performance for the master selected. If you want to use the hint /*+ ALL_ROWS */ you should write ALL_ROWS in this field. The select statement expands with /*+ and */. |
| Where clause | If the table is a master table you can write a valid where clause here to restrict the number of master records fetched. You should omit the word WHERE, which the select statement is expanded with. |
| Attribute List | |
| --- | --- |
| Column name | Name of the column. LOV. |
| Primary key | Shows which columns that are primary key for this table. |
| Parent Key Name | If the table is not a master table is must at least have one parent key name filled in. This is used to create the where clause between the parent table and the child table. Only the parent keys should be included here. |
| Seq No | Sequence no. Only used for ordering the columns. |
| Allow as Parameter | If the table is a master table one can check those columns that can be used as execution parameters. |
Actions for Data Archive Object¶
Generate Archive Package¶
Each data archive object must have a data archive package created before it can be executed. This action generates the data archive object PL/SQL package needed for the data archive process. It will download a file which should be deployed directly in the database using a tool like SQL Plus.
The data archive package holds the code needed for the data archive process to run the archive execution. After changing a data archive object it is needed to regenerate the data archive package so it reflects the changes. The only dynamic information is the master where-clause and the execution parameters.
The data archive package is named “archive_object”_ARC_API.
Note: If there is any trouble with creating of the data archive packages you might have to use DROP PACKAGE option in the form to drop the “archive_object”_ARC_API. After dropping the package you should be able to generate it again.
Generate Archive Storage¶
If the data archive destination is Oracle Table this action creates and downloads a SQL script file that can be used for creating the data archive destination tables. Deploy this file directly in the database using a tool like SQL Plus logged on as the destination schema owner. The script asks for data archive data and index tablespace and storage clause. It is possible to edit the file for setting own definitions.
Note: f there is any trouble with downloading the generated file please add the file extension which is 'CRE' as a value to the System Parameter "Allowed File Extensions except which are specified in DOCMAN and Media Extension". This is because some file extensions are restricted by default.
Drop Package¶
Drops the data archive object PL/SQL package.
Export Configurations¶
Exports the values for the data archive object to a SQL file that can be executed at another installation of IFS Cloud. This file can be included in a release and used in normal installation procedures.
Duplicate Object¶
Copies the data archive object to a new data archive object with a new name and description.
Check Master Statement¶
Checks if the master select clause is expanded to a correct SQL statement. Generates an error if anything is wrong. It is possible to copy the statement and try it in SQL*Plus or similar tool.
Data Archive Object Considerations¶
These information will helpful for you when you creating a data archive object
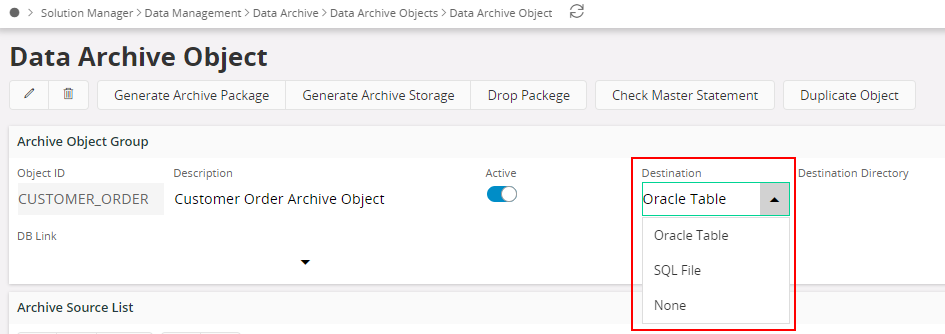
Data Archive Destinations¶
Data archiving objects can have its destination either to an SQL File, Oracle Table or to None (a non-destination). The destination directory is only important when you have chosen data archive destination SQL File. DB link is only important when you have chosen Oracle Table as a data archive destination and the destination tables exist on another schema or another instance.
SQL File¶
Moving data to data archive destination Sql-file requires to set up of the database so the database server can write on a server disk. Inserting one line for each directory in Oracle instance parameter initialization file Init.ora makes it possible for the database server to write to the server disks.
A data archive destination SQL File contains insert statements, pointing back to the data archive objects source tables, which restore all objects archived in a data archive execution for a specific data archive object. The rows in one data archive object instance is placed in a hierarchy with the master table first and then the masters' children and so on. No transaction handling is included in the files.
Files are named “archive_object””exec_id””archive_date”.txt, like CUSTOMER_ORDER_NO1_20000401_163204.txt.
#Sample init.ora file
#On NT
utl_file_dir=C:\production\archiving\customer_order
utl_file_dir=C:\production\archiving\maintenance
#On Unix
utl_file_dir=/production/archiving/customer_order
utl_file_dir=/production/archiving/maintenance
Note: When specifying utl_file_dir you must specify one row for each directory. You cannot access subdirectories without inserting one line for each subdirectory. The directory specification is case sensitive and you must spell the directory correctly. The owner process that runs Oracle must have operating system write access to the specified directories. If someone else should access the files, created by the database server, they must have operating system access to the files too.
Note: You must restart the database to set the utl_file_dir parameter.
For additional information see Oracle Manuals about Supplied Packages and read about the Utl_File package.
Oracle Table¶
Data archive destination Oracle Table requires that the destination tables are created either in the same schema or in a schema that can be reached by a database link associated with the data archive object. With a database link you can reach schemas on other instances that can reside on another machine. For performance reasons, its recommended to use a quick network connection to the destination instance.
Note: The database link must include a username and password. Anonymous database links will cause an error in the data archive process. Create the database link, either as appowner or as a public database link. Database links must be created with a SQL tool outside IFS Cloud. See Oracle manual SQL Reference for details about database links.
Example:
CREATE PUBLIC DATABASE LINK db_link_name
CONNECT TO archive_destination_username
IDENTIFIED BY archive_destination_password
USING 'service';
Remember that Init.ora parameter global_names defines how database links can be named.
A create table script file for the destination tables can be generated from data archive objects definitions. The create table script file can be executed in the database using SQL Plus to create the destination tables. Remember to log on to Oracle as the destination schema user.
Data archive tables are named as the source tables, except that their extension is “table_name”_ARC instead of “table_name”_TAB for source tables. Data archive tables are extended with 2 columns Data_Archive_Date(Date) and Data_Archive_Id(Varchar2(55)). The columns are used to identify which data archive execution that made the archive copy of the data. Data archive tables have a primary key called “table_name”_PKA, instead of “table_name”_PK for source tables.
None¶
None data archive destination alternative is included for creating of cleanup or for testing of data archiving executions. If using the None destination the only data archiving types that make sense for the tables in the data archive object is Move and Remove because they remove the object from the source tables. None or Copy will do nothing but can be used for testing of a data archive object.
Data Archive Type¶
Each table in a data archive object can have its own data archive type, which tells the data archive process how to handle the rows in that table. There are four different data archive types Move, Remove, Copy and None.
Move¶
Move copies the data to the destination, if the destination is not set to None, and removes the data from the source. This is the setting that should be used for normal data archiving either to SQL File or Oracle Table.
Note that Move will generate an error if the data has been run with data archive type Copy and data archive destination Oracle Table before, because then the data already exists in the data archive destination. The primary key index on the data archive destination tables will not allow duplicate rows.
Copy¶
Copy checks if the object exists on the data archive destination and if it exists it removes the object from the destination and copies the object to the destination and leaves the source as it was. Note that if the destination is SQL File the object will exist in many files over the time, due to it is not possible to remove the object from the destination SQL File. Copy can be useful for an object that exists and changes under a long period of time and it needs to be archived during that time.
Note that if archiving to archive destination Oracle Table only the latest version of every row is archived and the union of all child rows over the time is archived.
Remove¶
Remove just removes the object from the source. This setting should be used with caution though it just removes the data from the source table. It can be useful for creating cleanup executions with Data Archive Destination None. It also can be useful on tables in the hierarchy that is not wanted to archive for some reason, e.g. tables with historical data about its parent table like Customer order line history.
None¶
None performs no actual operation on the object, but simply walks through the object structure. This can be useful when performing tests on archive objects as they are being defined.
Example:
Lets say that we have an archive object customer order, with three tables: order head, order lines and deliveries and that each order consists of 1 order head, 10 order lines and 10 deliveries per order line. The archiving process will execute the rows like this:
- Get the order head
- Get the first order line
- Get all the deliveries
- Get the next order line and so on until all the rows for one order are processed and then process the next customer order.
Data archive object code used by the archive process is generated from its definition and stored in the database as a package. The data archive process calls for the generated code when it wants to start.