Migrate from File to single LU¶
INSERT_BY_METHOD_NEW, INSERT_OR_UPDATE, CHECK_BY_METHOD_NEW procedures can be used to migrate data directly from a text file to a single logical unit in IFS Cloud with less configuration.
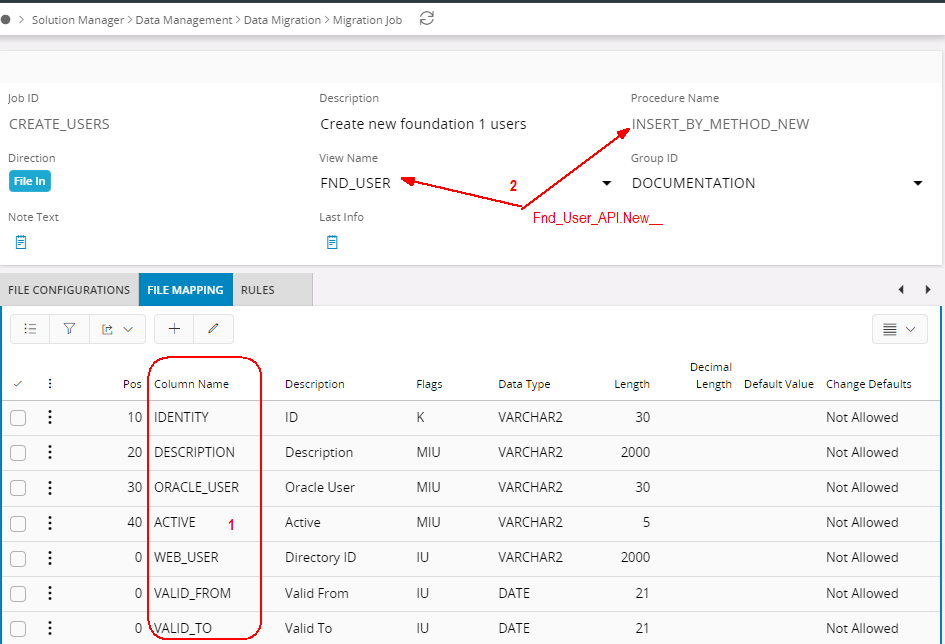
Using View Name in the Header¶
-
When you enter a View Name in the header, that view's columns will automatically be added to the File Mapping tab, when saving the job.
-
When starting the job, the View Name indicates what LU you want to update, as Data Migration will try to invoke
<view_name>_API.New__ or Modify__ depending on your choice of Procedure Name
Separated Files¶
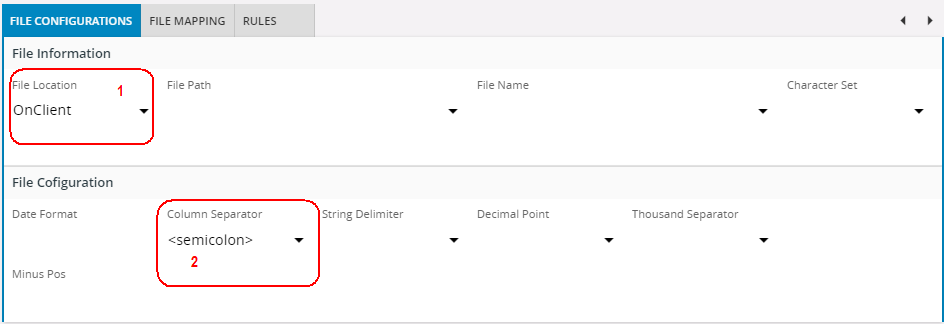
-
When specifying files On Client, you do not have to enter File Path, or File Name. You have to browse for the file before running the job, through RMB Option 'Load File'
-
Semicolon is a common field-separator but other characters can also be used.
-
Use Pos to indicate in which order the columns appear on the file. Intervals of 10 is recommended;
then it is easier to change position of single columns without having to re-sequence the whole list. -
The column length indicates the allowed length for this column in IFS. If the column length on the file exceeds this length, you may get an error-message, depending on how you specify the rule TRUNCVAL.
Fixed Format Files¶
. - If the file have a fixed format, the Column Separator is left blank. - Pos must specify the columns start-position of the file - And Length specifies the length of the column on the file. If the files length exceeds allowed length in IFS, adjust length accordingly. (Oracle's SUBSTR is used to read fixed format columns)
Note:- On fixed format files, columns may start with leading zeroes that you need to trim off. If this is a column of type NUMBER, this will happen automatically, but if it is of type VARCHAR2, you specify character
Building Attr-string¶
The columns with a given Pos or Default Value will be used to build the Attribute string for the New__/Modify__ method. For some of the LUs in our Business Logic, it is important that the items appear in a specific order (F.ex. COMPANY must be first item). The column Attr Seq is used to sort the items before building the Attr.string. If you have entered a View Name that generated columns, the Attr Seq will be sequenced in same order as if you DESCRIBE the view in SQL*Plus f.ex.(To be precise, it is the column COLUMN_ID from dictionary-view ALL_TAB_COLUMNS, multiplied with 10)
Now, if you have entered your columns manually, or need to reorganize the attr-string, simply update Attr Seq to obtain the sequence you need.
Handling File Headers¶
-
Very often we get files that have a file header (when generated from Excel f.ex). Instead of removing this file header each time a new file arrives, we may specify Rule SKIPLINES to always skip the first n lines.
-
If we have a separated file with a file header that contains the correct column-names for the LU we are going to update, we do not have to specify any Pos in folder File Mapping; we can activate Rule SYNCDETAILS and Data Migration will automatically map the columns in given order. Columns from the file header that does not exist in the LU, will be treated as dummy-columns and ignored (length=0).
Other Relevant Rules¶
| Requirement | Rule |
|---|---|
| What to do if file contains format errors (NUMBER, DATE) | IGNOREADERROR |
| What to do on errors when inserting/updating selected LU | IGNOREXEERROR |
| Perform either UPDATE or INSERT | INSUPD |
| Keep lines for client files, even if job is OK | NOCLEANUP |
Error Handling¶
Error handling of file jobs is described here>>