Incremental Load of Information Sources¶
An Information Source supports two data access types - Online and Data Mart access. The Data Mart version is based on snapshot tables that contains calculated and derived data. Originally it was only possible to implement snapshot tables by using Materialized Views in the Oracle database. The Data Mart framework has been extended to also support incremental load of Information Sources. The incremental load framework supports both Facts and Dimensions, but implementation have so far only been made by the product teams for Facts.
The facts are the main targets since the fact definitions are often rather complex and they also represent transactional data. Introducing incremental load possibilities gives a very big advantage compared to the solution based on Materialized Views. Except for the first/initial load it will be possible to only recalculate data related to a small sub set of all available transactions and thus enhancing the refresh time considerably. The solution based on Materialized Views only handles complete refresh.
Framework Comparison¶
The Data Mart framework based on Materialized Views can be visualized as follows:
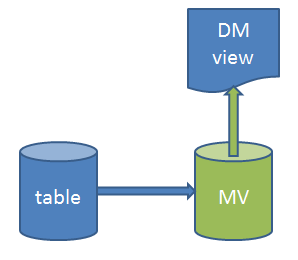
Figure 1: Data Mart access based on Materialized View
- A Materialized View (MV) is created that reads all necessary data from one or more source tables (or even views). The complexity of the MV expression can be affected by joins, sub selects, groupings and especially by calls to functions in the LU entity packages.
- A Data Mart (DM) view is created that reads from the Materialized View. The DM view is then the read interface for the the fact (or dimension) entity when it comes to Data Mart access.
- Refresh of a Materialized View will always be a complete refresh. This is due to the complexity of the Materialized View definition. Another reason is that Oracle's support for incremental refresh, using Materialized View Logs, has many limitations and may also cause problems with archive logging etc.
The extended Data Mart framework supporting incremental load can be visualized as follows:
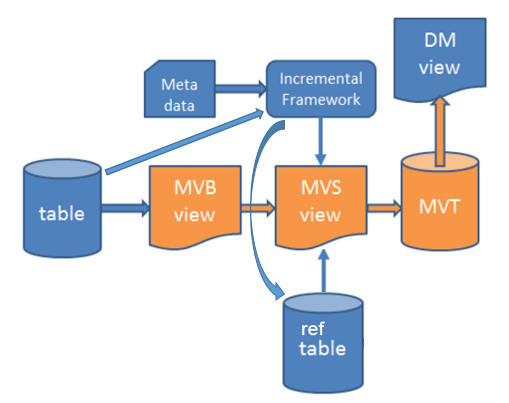
Figure 2: Data Mart access based on incremental load
- A base view (MVB) is created that does the actual select of entity information. This view is then more or less similar to the Materialized View expression.
- The incremental framework will create the source view (MVS). The advantage with this view is that it may contain filter conditions in order to reduce the number of records fetched via the MVB view.
- A snapshot table (MVT) is created. This table is for the incremental case a replacement for the Materialized View and it is an ordinary Oracle table.
- Metadata has to be developed for the entity that should support incremental load. Development is performed in IFS Developer Studio.
- The incremental frameworks will take care of refreshing the MVT table by reading the MVS view. If refresh has not been performed before, the refresh operation means that a full refresh will be performed. After this the refresh operation means incremental refresh.
- The Data Mart (DM) view in this case reads from the snapshot, MVT, table. The contents is more or less the same as when reading from a Materialized View. The DM view is the read interface for the the fact (or dimension) entity when it comes to Data Mart access.
- The framework keeps track of changes in referenced source tables and will during incremental load create one or more temporary reference tables with keys that are used in combination with the source view (MVS) in order to only transfer new/modified source rows to the snapshot table (MVT).
Functional Overview¶
The framework for incremental load supports the following functionality:
- Full refresh
- Incremental refresh based on changes in source tables referenced by the entity (typically references via the MVB view)
- Delete of records in the MVT table that does not exist in the source, i.e. by comparing with the MVB view
- Possibility to define a set of conditions to be applied to the MVS view, basically with the purpose to reduce number of records to process
- Sub Set refresh
- A specific set of conditions (criteria set) can be defined that represents a sub set of all records, e.g. all transactions entered the last year.
- The criteria set can be used when performing a sub set refresh, i.e. reading a sub set of all transactions, processing them and replacing them in the snapshot (MVT) table
- Support for references to tables in dynamically dependent components
- Aurena pages covering:
- General information about entities supporting incremental load
- Information about source tables that affect the status of the entity, i.e. a change in one of the listed tables leads to that the entity specific MVT table is no longer up-to-date. The latest timestamp in each affected table will also be visible.
- Criteria sets, i.e. one or more identities representing a set of conditions to be applied either to the MVS view or when performing sub set load.
- Refresh operation logging
Data Mart Based on Incremental Load¶
Some words about the Data Mart based on incremental load.
- Ordinary tables are used as snapshot tables or storage containers for Dimensions and Facts. Incremental load is mostly suitable for facts.
- Data can be derived or calculated when accessed via the MVS view. This means that the snapshot (MVT) table will contain these derived/calculated values, thus enhancing performance when accessing the data view than Data Mart view compared to reading from the Online view.
- The snapshot (MVT) table can be indexed according to customer/installation specific needs without doing any changes in ordinary core tables.
Refresh Options¶
The following refresh options are available:
- Full refresh (might consider conditions added to the MVS view)
- Incremental refresh (using the MVS view as source)
- Sub Set load using the MVB view and a set of conditions that defines the sub set.
Considerations¶
Some considerations when creating objects related to incremental load:
- MVB view The MVB is the main view that that represents how to retrieve the data related to the entity. The more complex the view is, the risk for bad performance is increasing. Always try to make the view as efficient as possible. If possible, avoid function calls. It is sometimes possible to replace the function calls with ordinary joins.
-
Columns to be considered The MVB view normally contains one column less than the MVS view and the MVT table. The MVS view and the MVT table should have matching columns. The Online view for the entity should define more or less the same columns as in the MVB view.
-
Limit number of transactions
Reducing number of transactions transferred to a snapshot (MVT) table is one way to improve the transfer performance. Conditions can be defined in a form in IFS Cloude as a criteria set and this set can be attached to the entity leading to that the MVS view is created with conditions. The conditions will be in effect both for full and incremental load. -
Translation handling
Translated texts should in most cases not be stored in the snapshot (MVT) table, since the language is decided at the time of execution. The solution is to move retrieval of translation specific values to the Data Mart view. Some examples are client values related to Enumerations, basic data translations and company specific translations. - User Specific Data Data that is dependent on the current user should not be stored in the snapshot (MVT) table. The solution is to move retrieval of translation specific values to the Data Mart view.
- Row Level Security
Row Level Security should note be implemented as a part of the MVB view since security has to be evaluated at the time of access with respect to current user. The solution is to move retrieval of translation specific values to the Data Mart view. - Indexes
A big advantage with snapshot tables is that purpose built indexes can be added without too much concern compared with adding indexes to core tables.
Do not add too many indexes to the snapshot (MVT) table since it is difficult to find out in advance how different customers will access the data in the table. Add indexes on columns expected to be the most commonly used ones and use concatenated indexes, e.g. combining two or more columns, rather than single indexes. - Refresh Time
The initial refresh will always lead to a full load, reading all records as defined by the MVS view and storing them in the MVT table. This initial refresh can take rather long time depending on the complexity of the base (MVB) view and if there are any filter conditions defined or not to reduce the number of records. Incremental load can be very fast but it is not by default fast. Some things to remember:- Changes in referenced tables might lead to that many records are affected. Since each and every fetched row will have to be processed before it is stored it can still take a long time. The fewer rows affected the faster it will be.
- Available indexes and the size of each involved table in the refresh process will also affect the refresh time since it can take a while to find the changed rows since last and also to find affected rows in the parent table. How the refresh mechanism works can be found in the development section.
How it Works¶
The general principle used by the framework will be explained in this section.
Assume that we have a Fact where the associated access views are retrieving information mainly from the tables CUSTOMER_ORDER_TAB and CUSTOMER_ORDER_LINE_TAB. Analyzing the Fact views, e.g. the function calls, leads to that there are two more tables that are involved when retrieving the Fact information; CUST_ORDER_LINE_TAX_LINES_TAB and CUST_ORDER_LINE_DISCOUNT_TAB.
A structure describing the table dependencies must be defined. For the example case it is possible to define two structures. The first alternative is to use the following structure: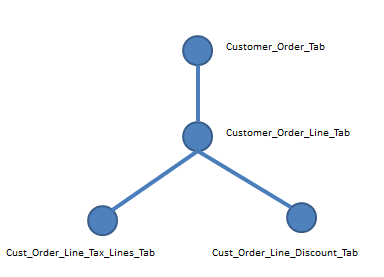
Figure 3: Table dependency structure - alternative 1
In this alternative the table CUSTOMER_ORDER_TAB has been defined as the top table. CUSTMER_ORDER_LINE_TAB is a child table to CUSTOMER_ORDER_TAB but at the same time acts as a parent for the other two tables. The framework will keep track of changes in all four tables and propagate the changes up in the dependency hierarchy. The end result will be a collection of keys in the top most table, i.e. order numbers in table CUSTOMER_ORDER_TAB, that defines the orders affected by changes on all levels.
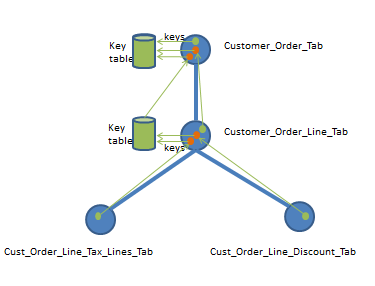
Figure 4: Table change handling - alternative 1
Changes are in the above model handled as follows:
- Changes in table
CUST_ORDER_LINE_TAX_LINES_TABleads to that related keys in the parent tableCUSTOMER_ORDER_LINE_TABare collected in a key table, say ColKeyTab. - Changes in table
CUST_ORDER_LINE_DISCOUNT_TABleads to that related keys in the parent tableCUSTOMER_ORDER_LINE_TABare collected in key table ColKeyTab - Changes in table
CUSTOMER_ORDER_LINE_TABleads to that related keys in the parent tableCUSTOMER_ORDER_TABare collected in a key table, say CoKeyTab - The collected keys in the
CUSTOMER_ORDER_LINE_TABrelated key table ColKeyTab leads to that related keys in the parent tableCUSTOMER_ORDER_TABare collected in key table CoKeyTab. - Changes in table
CUSTOMER_ORDER_TABleads to that keys in this table are collected in key table CoKeyTab - The keys in the highest level table CoKeyTab are now used by the framework to select and process information/data for only these keys, removing the corresponding records in the snapshot (MVT) table and replacing them with new and modified records.
The second alternative is to create a dependency structure as below:
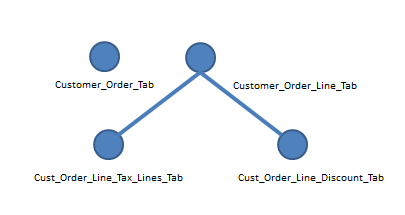
Figure 5: Table dependency structure - alternative 2
In this alternative the tables CUSTOMER_ORDER_TAB and CUSTMER_ORDER_LINE_TAB have been defined as top level tables. The framework will keep track of changes in all four tables and propagate the changes up in the dependency hierarchy. The end result will be a collection of keys related to CUSTOMER_ORDER_TAB and CUSTMER_ORDER_LINE_TAB.
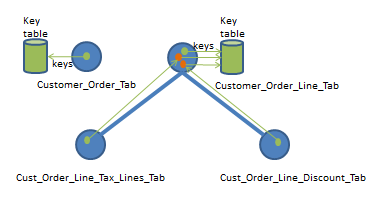
Figure 6: Table change handling - alternative 2
Changes are in the above model handled as follows:
- Changes in table
CUST_ORDER_LINE_TAX_LINES_TABleads to that related keys in the parent tableCUSTOMER_ORDER_LINE_TABare collected in a key table, say ColKeyTab. - Changes in table
CUST_ORDER_LINE_DISCOUNT_TABleads to that related keys in the parent tableCUSTOMER_ORDER_LINE_TABare collected in key table ColKeyTab - Changes in table
CUSTOMER_ORDER_LINE_TABleads to that keys in this table are collected in key table ColKeyTab - Changes in table
CUSTOMER_ORDER_TABleads to that keys in this table are collected in a key table, say CoKeyTab - The keys in the highest level key tables CoKeyTab and ColKeyTab are now used by the framework to select and process information/data for only these keys, removing the corresponding records in the snapshot (MVT) table and replacing them with new and modified record
In general the second alternative is to prefer since it will reduce number of affected records compared to the first alternative.
- If in the first alternative one single customer order line has been modified, it still means that all customer order lines associated with the Order Number of the modified row will be handled.
- In the second alternative only the modified row will be handled since the there are two separate top master tables.
Development¶
How to develop support for incremental load is described in section Incremental Load Development as part of the IFS Cloud development guide.