Data Archiving¶
Data archiving is a concept for moving a data archive object from the production database to another media. A data archive object consists of one or more database tables that hold transactional data for the same business object e.g. customer order. As of today the data archive object can be moved to another database or to a file with SQL-statements on the database server file system. Data archive orders are also defined to schedule when the data archiving process executes the data archive objects.
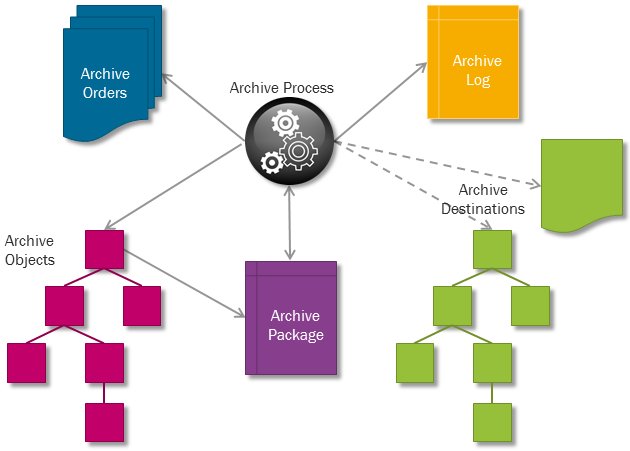
Schematic view of the Data Archiving concepts and their relations
The main reason for archiving data is to get rid of unused transactional data in the production database for performance and sizing reasons.
Note: There is no functionality for viewing archived data in the original client forms within IFS Cloud.
As of now custom forms for viewing archived data will have to be created to do this.
Data Archive Objects¶
Data archive objects are intended for transactional business objects like customer orders, financial transactions or invoices, that the system can still work without. Data archive objects are not intended for system data like accounts, customers or products. There are some business objects that are between transactional business objects and system data like product structures, organizational hierarchy or sales parts. Data archive objects can be defined for these objects, but it will be of great importance that these objects have some kind of status attribute that shows that they are not in use anymore.
When defining a data archive object it is important that you keep the definition to one business object. For example: if you want to archive a customer and all of its corresponding customer orders, you must do this as two data archiving objects, customer and customer orders. It’s not suitable to archive this in the same data archive object because it becomes too complex.
Before archiving the data archive objects that you have defined you must be sure of that all areas of IFS Cloud have finished using the object. It’s also of great importance that all statistics (updates and reports), transformation to data warehouse objects (IAL and cubes) and so on have been done.
A data archive object is a definition of one ore more database tables in a tree structure. The tree structure starts with the parent table called the master table. The master table is the driver for the whole data archiving process. You define a where clause for the master table and the data archiving process fetches each master record that fulfills the where clause. For each master the whole tree structure of tables is processed. For each table you can decide what you shall do with the data:
- Move: copies data to destination and then removes it from the source. This is the normal archiving behavior.
- Removeonly: deletes the data at the source. If all tables have the remove type we have created a cleaning process. One other useful way of using remove can be to combine move and remove, where you can use remove for tables where you don’t want to archive the data e.g. order line history.
- Copy: first deletes the same object on the destination, if it exists, then it copies the source to the destination.
- None: performs no actual operation on the object, but simply walks through the object structure. This can be useful when performing tests on archive objects as they are being defined.
An example: Lets say that we have an archive object customer order, with three tables: order head, order lines and deliveries and that each order consists of 1 order head, 10 order lines and 10 deliveries per order line. The archiving process will execute the rows like this:
- Get the order head
- Get the first order line
- Get all the deliveries
- Get the next order line and so on until all the rows for one order are processed and then process the next customer order.
Data archive object code used by the archive process is generated from its definition and stored in the database as a package. The data archive process calls for the generated code when it wants to start.
Follow this link to read about the Data Archive Objects form and the activities you can perform here.
Data Archive Orders¶
A Data Archive Order defines when and what to archive in one execution. It contains a scheduling information record and a collection of objects to be archived at the same time.
The scheduling information defines when the order shall execute next time and how to schedule future executions.
Each order consists of one or more data archive objects to be executed, called Data Archive Executions. Each execution can have specific parameters values which affect the master table's where clause.
The intention with orders and executions is that it should be possible to archive for example, five archive objects in a specific order, for one specific company on Mondays and schedule the same operation on Tuesdays for another company.
Follow this link to read about the Data Archive Orders form and the activities you can perform here.
The Data Archive Process¶
The data archive process is the process that executes all archiving.
- Wait until its time to wakeup, depending on the system parameter Data Archive process startup interval.
- Get data archive orders that have a next order date less than current time and are set to active. The archive orders are sorted by next execution date and order id.
- Set next order date for the data archive order with information from the execution plan.
- Get all data archive order executions that are active, sorted by sequence no.
- Get all the master rows for the data archive object connected to the execution. For every master, restricted by master where-clause and execution parameters, set a savepoint, move the master to archive destination.
- Get the all rows for the master’s first child table. Execute the first child row, move the child row to the data archive destination. Archive the child’s children and so on. When getting back remove the child row. Process the next child row.
- When all children are processed, remove the master. If everything goes right, commit the transaction and process the next master. When all master rows are processed, write to the archive log. If anything goes wrong rollback to savepoint and write to the data archive log and exit the execution. Triggers the event Data Archive Executed if event is enabled.
- Process the next execution and when all executions for one data archive order are executed; Get the next data archive order.
- When all data archive orders are finished go to sleep and wait for next time to wakeup.
Follow this link to read about the How to Setup Data Archiving and what parameters control the process.
Data Archive Packages¶
The data archive packages are generated PL/SQL packages that retrieve and archive data when data archive orders are executed.
Data Archive Destinations¶
The target for the archived data, may be tables or files.
Data Archive Log¶
The log keeps information about and status of the executions of the archive orders.