Tips & Tricks - Connected Jobs¶
Data Migration is often used to set up jobs, where a file is loaded from a server into a table in one job, and then a second job does the actual update of IFS. Below is a description of how you connect two such jobs, ensuring that both execute successfully, and that error rows are taken care of. Then these jobs may be started as background processes, for repetitive execution.
Connect Two Jobs¶
As an example, let's try to insert some users from a file to IFS Application using two migration jobs.
Sample Data (Fnd_user.csv)
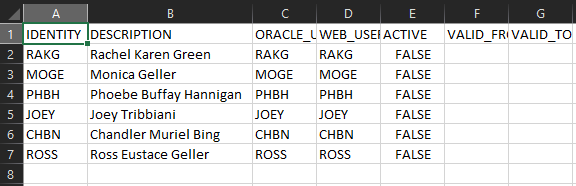
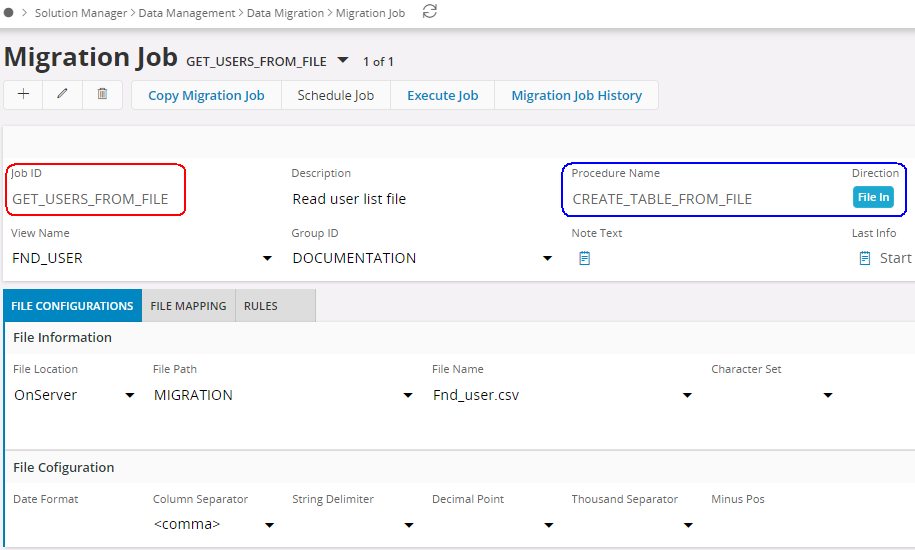
- Create the first migration Job to generate a table using a file. ex: GET_USER_FROM_FILE. The Job should be created with procedure CREATE_TABLE_FROM_FILE. Set the File Location to OnServer and fill others.
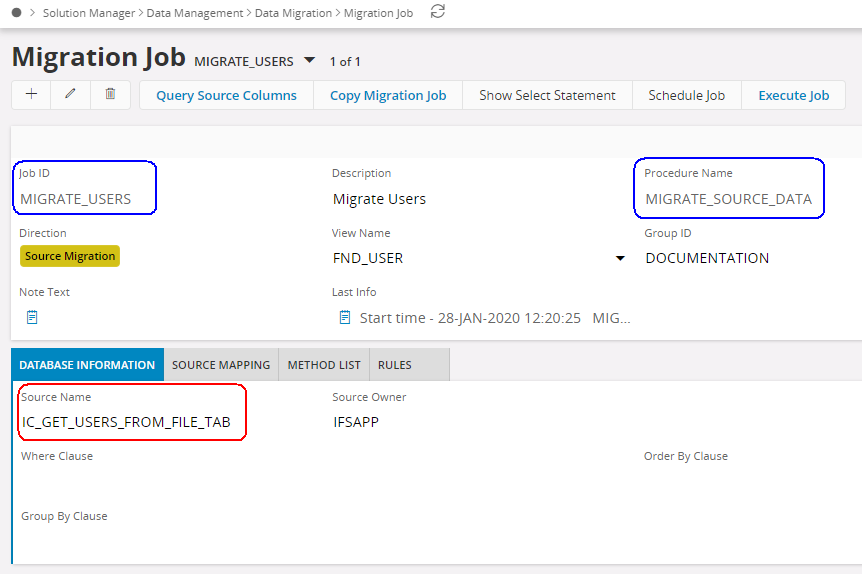
- Create a second job using the procedure, MIGRATE_SOURCE_DATA. eg. MIGRATE_USERS.
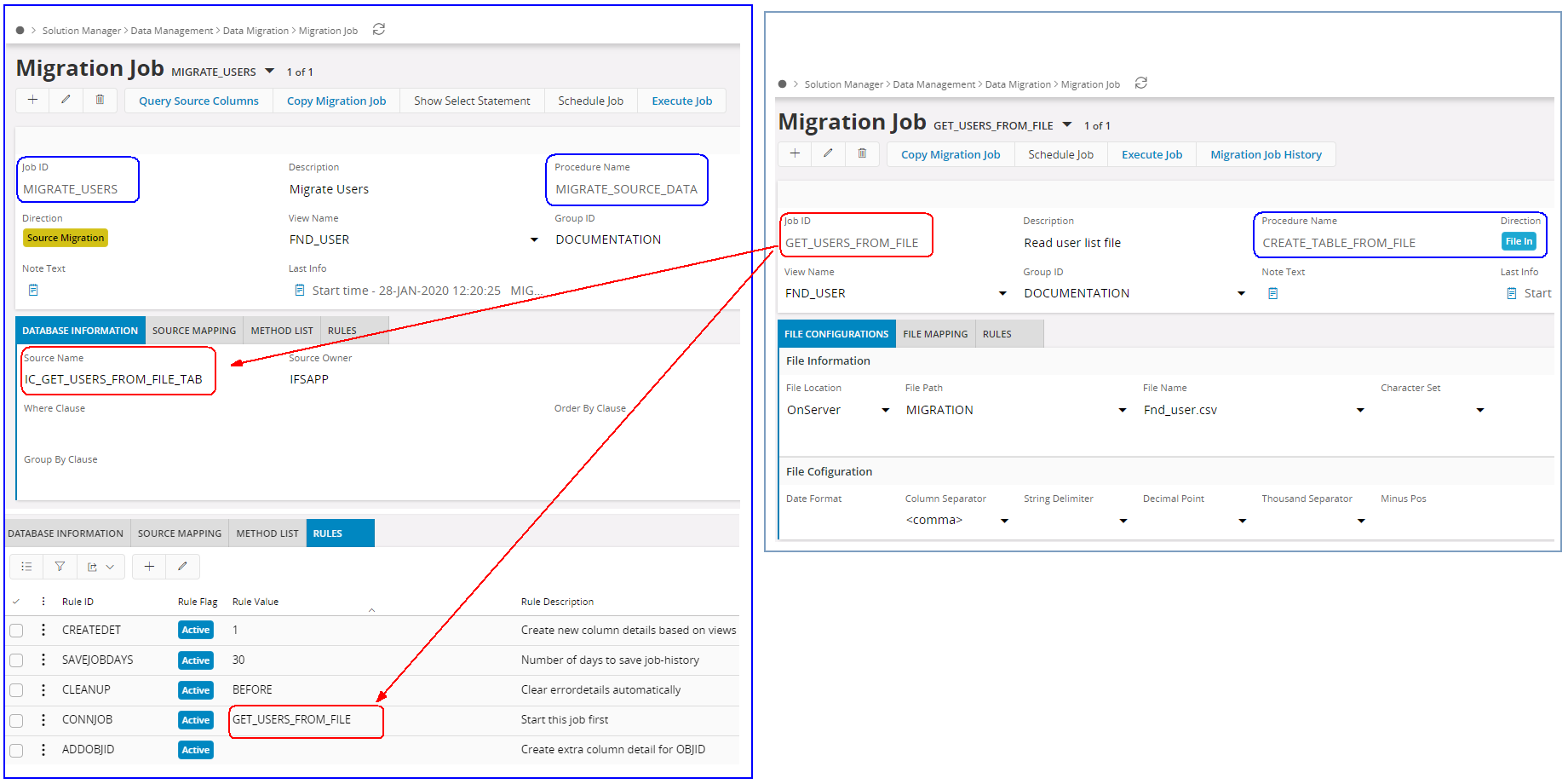
- Now we can connect the MIGRATE_USERS Job by using the Source Name as the IC_TABLE from the GET_USER_FROM_FILE job and activating the rule CONNJOB referring to GET_USER_FROM_FILE job.
Start Other Jobs From Method List¶
You may also start other jobs from the Method List, normally BeforeLoop or AfterLoop , using Intface_Header_API.Start_Job as a method.
Since we need to start the GET_USERS_FROM_FILE job from MIGRATE_USERS job we should mention that in Method list and the Method list attributes as follows.

The Method List Attributes look like this:
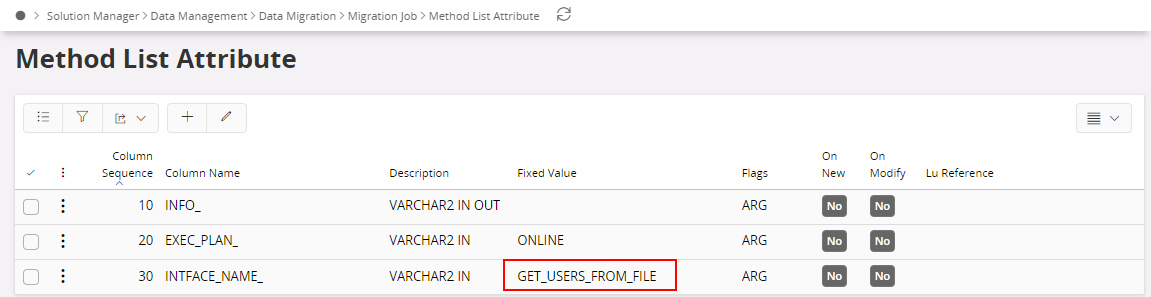
- Exec_Plan is already filled in with Fixed Value ONLINE. Do not change this
- Enter the name of the job you want to start.
Note: The procedure Intface_Header_API.Start_Job will not raise any exception if the specified job fails, and Data Migration will continue executing if you have more rows in your Method List.
Use procedure Intface_Header_API.Start_Job_From_Server if you want the whole execution to stop if started job fails.
Error Handling¶
Note: If there is a formatting error on the File job (date/number formats) both jobs stop and the error must be fixed.
But if errors occur on the Migration job, we can set up automatic handling of these errors:
In case of a source migration error in the previous job setup,
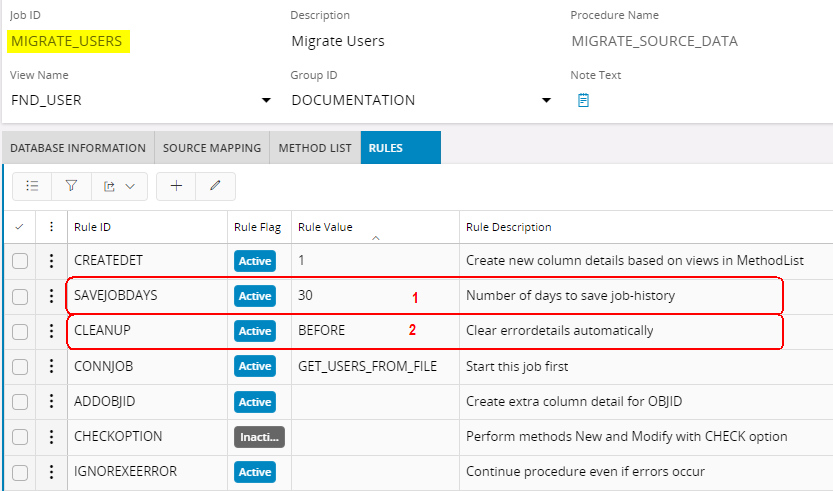
- Activate Rule SAVEJOBDAYS SAVEJOBDAYS on the Migration job
- Define Rule CLEANUP CLEANUP -->with option BEFORE on the Migration job.
This means that errors will be available for the query in Detail tab of the execution form after the job is executed, but will be moved to History tables at the beginning of next execution. - Activate Rule CRETABCONF CRETABCONF --> with option KEEPERR on the File job.
Then Data Migration will check if errors have been moved to history (previous step) and move corresponding rows from the IC_xx_BKP table back into the IC_xxx_TAB.
This means that errors that occur will not disappear, but will be used as input to the Migration job until the cause of the error is fixed.
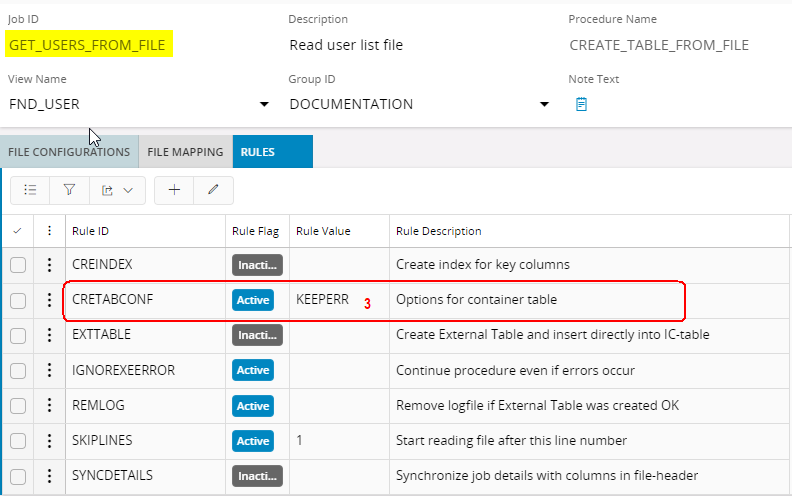
- Now we only have to start the Source Migration job, and this will start the GET_USERS_FROM_FILE job first and MIGRATE_USERS.
- Check the Last execution information for validations.

- See the results in User forms. Since the File Location is set as OnServer, these jobs can be used as a recurrent job with different files.