File Migration - Create Table from File¶
One of the common use of Data Migration is to read and fetch data from a file and load into a container table IC_<JOB_ID>_TAB by the process. In here we do not insert data directly to the logical units in Business logic. Hence it is quite safe to use this migration type if you have quite sensitive data because it allows you to check migrated data by reading frin the <IFSINFO> user schema.
This is a widely used migration type, in data migration and often used along with a Source Migration job as startup job to fetch data.
Create Table from File Migration Job¶
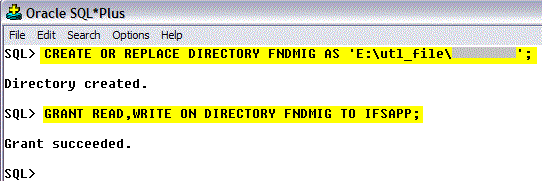
- Create a new data migration job using Migration Job form and enter values for Job ID, Description. Importantly, Set the Procedure Name to CREATE_TABLE_FROM_FILE. Group ID, Note Text, View Names fields are optional. The table name will be derived from the Job ID, using this convention: IC_<JOB_ID>_TAB. For the job below, the table-name will be IC_LOAD_CUSTOMER_FILE_TAB. Note that a table name can not exceed 30 characters (Oracle restrictions), so the Job ID itself must not exceed 23 characters.
- Select the File Location. In File Configuration Tab.
There are two ways to load files. they are OnClient, OnServer mode. Select accordingly.
In here we explain the OnClient File Loading and read more information for OnServer File Loading.
A file can be uploaded by functionality in the client. The file can be read from any folder accessible by the client. Files read by the client must be encoded in the client characters set. If the file is not encoded in the clients character set, characters not recognized will be lost when the file is saved to the database. - Select other relevant fields according to the jobs' needs. Such as Column Separator, Decimal Points, Date Format etc.
- Save the Migration Job.
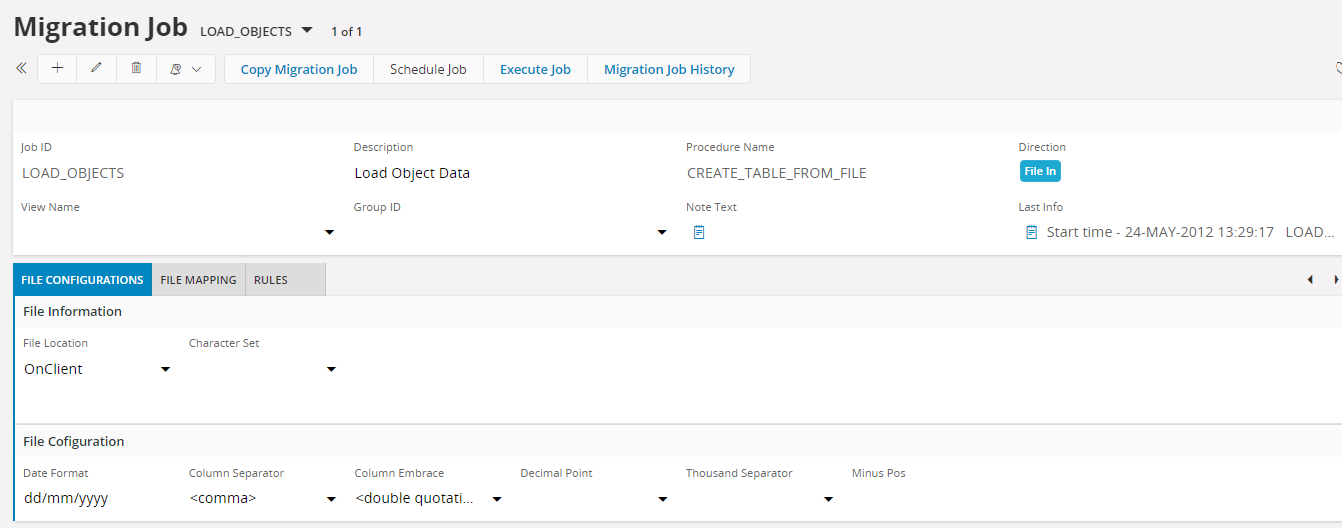
- Next, set the table column mappings according to the file in File Mappings Tab. Here you can set the data type, length, default values etc. At the time of execution, it will use the details in this tab to make the IC_TAB. In here, the Columns can enter manually, or enter a suitable view in the View Name column in the Migration Job header, so that it populates the columns automatically to this tab. After that, you can remove or modify the columns according to the data in the file.
- After that, set Pos (Position) values of the columns, that corresponding to the data in the file. The data in the file fetch according to this order. For files that have no separators the value in Pos is the starting position of the value and the length is the number of characters for the value. When positional notation is used and the file is encoded in a multi byte character set Length in File Mapping tab must be expressed in number of bytes.
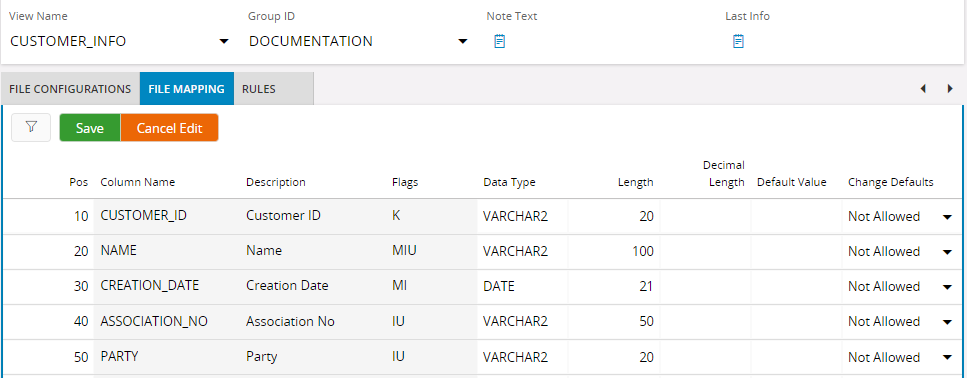 7. The Rules tab tab is populated automatically with rules that apply to the type of job created.
Finally, apply the wanted rules in the RULES tab. Rules Tab populates automatically with defaults rules to the type of job created. You can add other wanted rules.
7. The Rules tab tab is populated automatically with rules that apply to the type of job created.
Finally, apply the wanted rules in the RULES tab. Rules Tab populates automatically with defaults rules to the type of job created. You can add other wanted rules.
Execute File Migration Job¶
With a properly defined Migration Job, you can start the Job From Execute Job form.
- First set the input parameters accordingly. (If any)
- Next is to load the content of the file. This depends on the File Location given in the migration job and in here we explain the File Location OnClient. For the execution of jobs with OnServer File location, please check >>
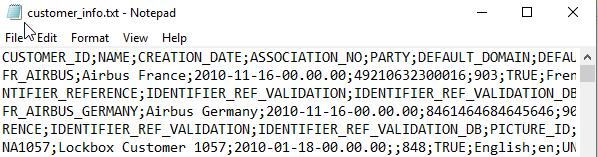 Data Sheet.
Data Sheet.
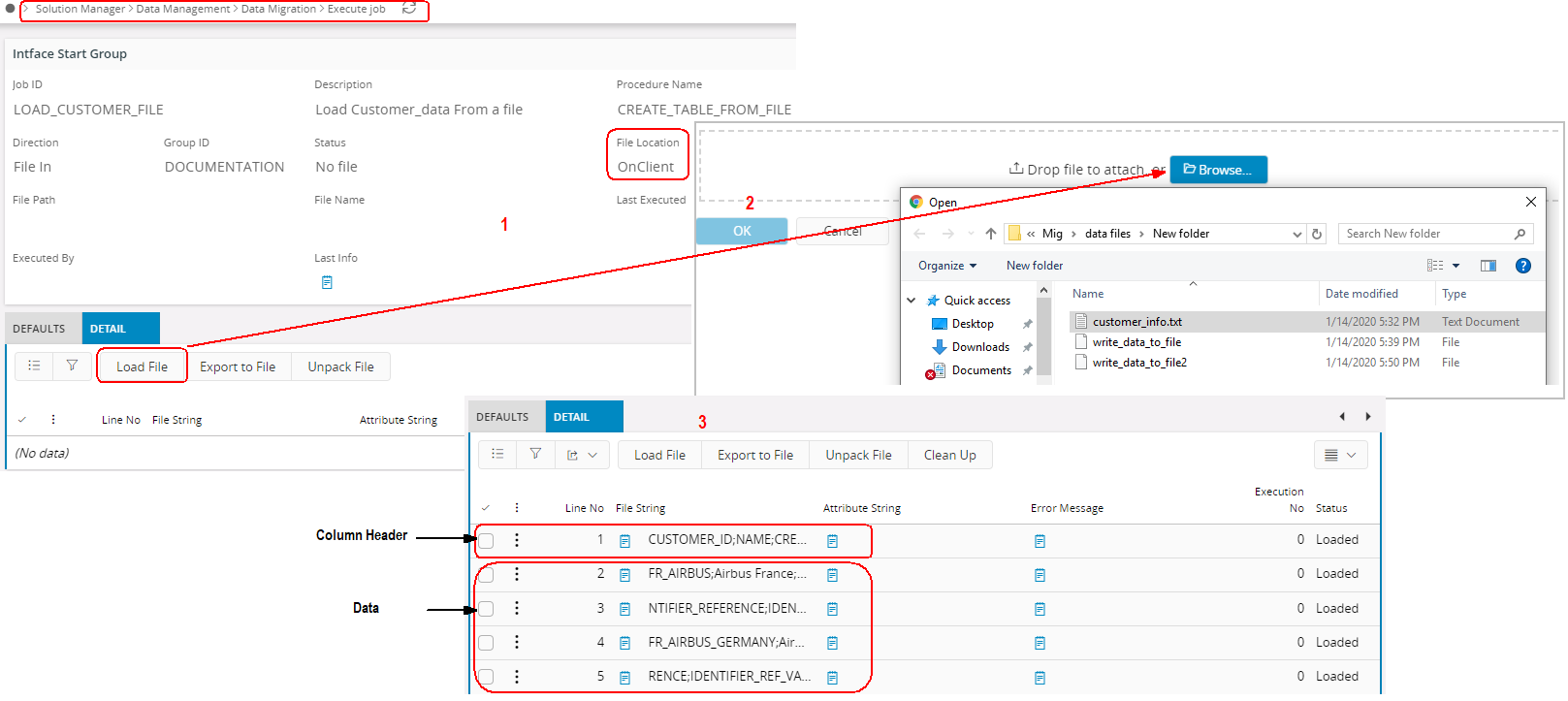
- Load Data command will open a browser dialog, which you can either browse for the file or drag and drop a file.
- Once you click OK, it will load all the data in the file to DETAIL Tab including column headers if any. In such cases, you can ignore the first line by using the SKIPLINES Rule as mentioned above.
- When loading the file there is a limitation for files with Unicode character set without a BOM (Byte Order Mark), the characters will not be read properly. Therefore, the workaround will be to convert the file to a Unicode character set which has the BOM and do the loading.
- As the last step, now you can use the Start Job > Online or Background button to start the migration process which creates the IC Tables and start inserting the data.
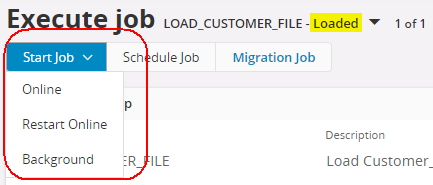
- Finally, you can see the log.
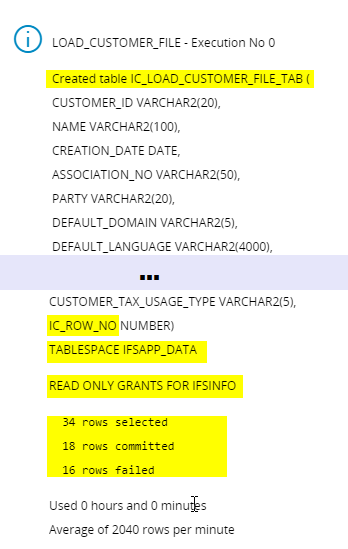
According to the log, you can decide whether you want to run it again or not.
Table name and Table Backup¶
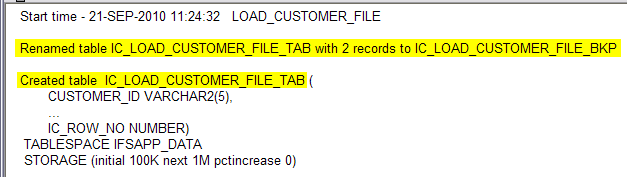
*When executing, a container table name IC_<JOB_ID>_TAB will create. If a container table already exists, it will rename to IC_<JOB_ID>_BKP as a backup table. There will be only one backup table. Existing ones will drop before renaming the IC_BAK.
IC_TAB is granted with read-only access to <IFSINFO> user. Meaning that if access is provided to the <IFSINFO> user account it is possible to read from the table.
File Line Sequence¶
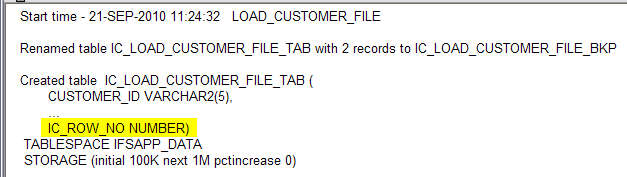
When a container table created the column IC_ROW_NO is always added. This column contains the sequence order in which the rows load from the file. It can use in later processing to order the rows in the container table if the order of rows is significant.
Index and Storage Parameters¶
If a container table is used in a JOIN with other tables/views in later processing an index on the table can speed up processing.
 *
When rule CREINDEX is Active an index will be created on the column(s) that have Flags = K or P in the File Mapping tab. With Rule Value = UNIQUE a unique index is created.
*
When rule CREINDEX is Active an index will be created on the column(s) that have Flags = K or P in the File Mapping tab. With Rule Value = UNIQUE a unique index is created.
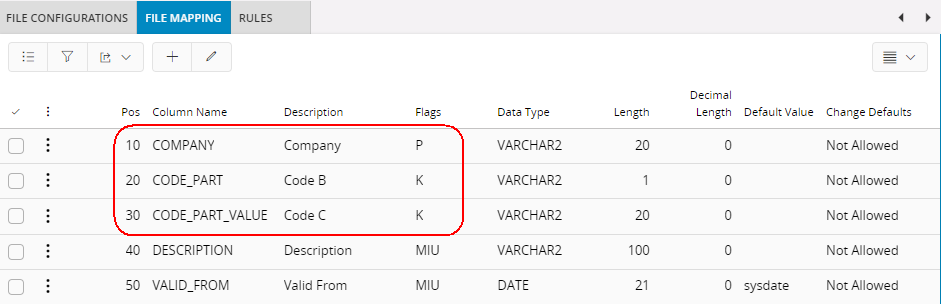
If more then one column is indexed a concatenated index is created. Use the Attr Seq column to specify the order of the columns in the index.
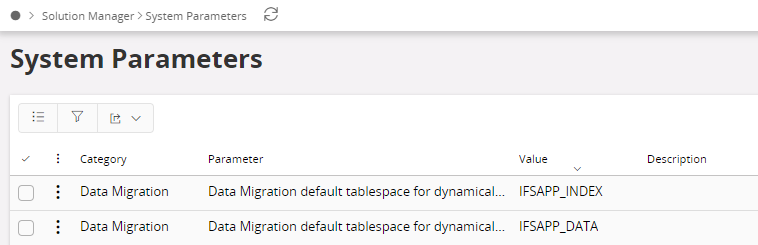
Storage parameters used when container tables are created are maintained in System Parameters.
Error Reports¶
Errors may occur for several reasons. The execution Log or the Last Info shows the number of rows selected from the file, the number of successfully processed rows (committed) and the number of failed rows.
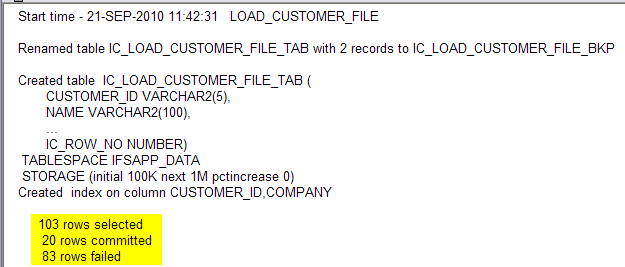
In the DETAIL tab Status is shown for each line and Error Message for failed lines.
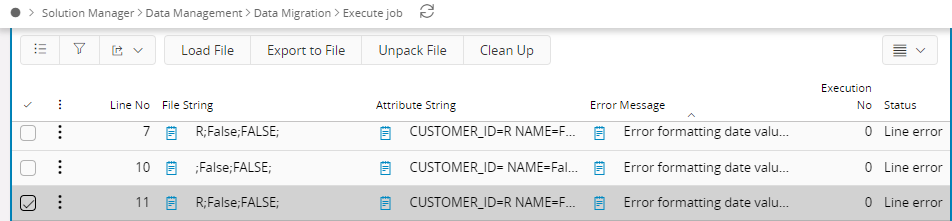
If you want to restart the job due to a data error in the file, clear the DETAIL tab using the Clean Up button and reload the file to start the job.
If the error is due to some definition in the migration job, fix it and restart the job.
File Path¶
The List-Of-Values on File Path contains a list of folders accessible to the Oracle server process on the database server. The List-Of-Values is populated with folders specified in the Oracle database initialization parameter UTL_FILE_DIR and folders specified as DIRECTORY OBJECTS.
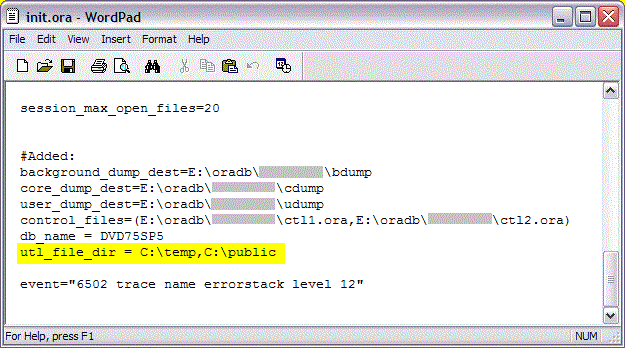
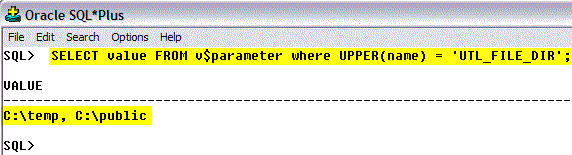
Using the parameter UTL_FILE_DIR is an old method and is no longer recommended. If it is used the database has to be restarted when the parameter is changed.
The recommended method is to use directory objects. Directory objects can be created by an Oracle system account and granted to the application owner or by the application owner itself in which case no grant is needed.