Converting a database to Unicode using DMU¶
In this section it is described how you can convert a customer database running with single-byte character set to a Unicode character set database using Oracle Tool DMU (Data Migration Assistant for Unicode). Read more about Unicode at About Unicode.
Introduction¶
If you are using DMU to convert a database you work with just one database and you converts this database from single byte character set to Unicode character set (AL32UTF8). The recommended way is to upgrade Oracle and IFS Cloud (if needed or planned) before upgrading the database to Unicode.
Prerequisites and Settings¶
You need to install DMU on a machine that can connect to the database you want to convert to Unicode. You will find information about DMU here.
Make sure that you use AL32UTF8 as the database character set.
Set parameter NLS_LENGTH_SEMANTICS=CHAR in init<SID>.ora or in your spfile before creating any database object in IFS Cloud.
Always perform a full backup before starting an operation like this so that you are sure that you can come back to the same restore point as when you started.
Steps performed in DMU¶
These are the steps you need to perform to be sure that your database is converted to Unicode.
- Create connection
- Install repository
- Scan the database
- Cleansing the data in the application
- Cleansing the data in the Data Dictionary
- Converting the database
- Validating data as Unicode
Create connection¶
First you must create a database connection. This is done under File/Create New Connection in DMU
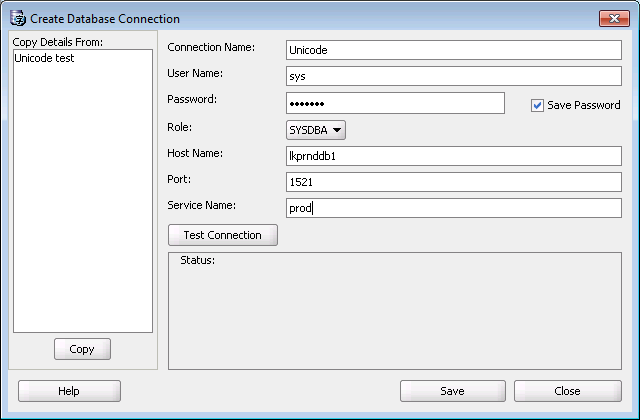
We recommend that you use SYS as user name since the connection requires the SYSDBA role. Verify your connection by clicking Test Connection.
Install repository¶
First of all you need to install the DMU repository if it doesn't exist.
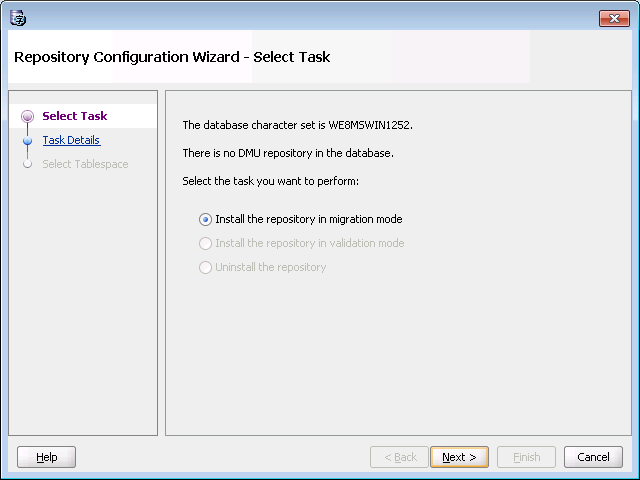
Click Next
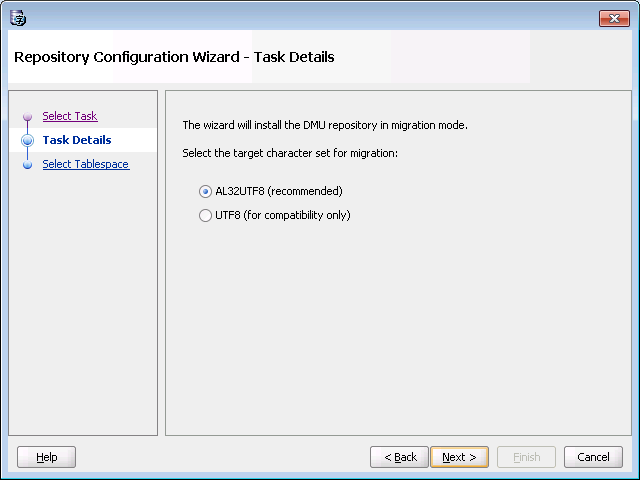
Make sure to choose AL32UTF8 as the target character set.
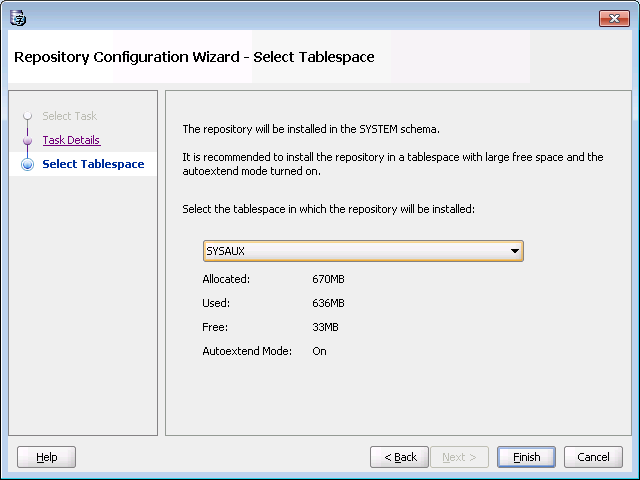
Choose SYSAUX as the tablespace if possible.
Scan the database¶
After you have installed your repository it is time to scan your database for potential problems upon conversion of the database. After the scan you can view all your potential problems in the Database scan report.
You scan your database by using Migration/Scan Database...
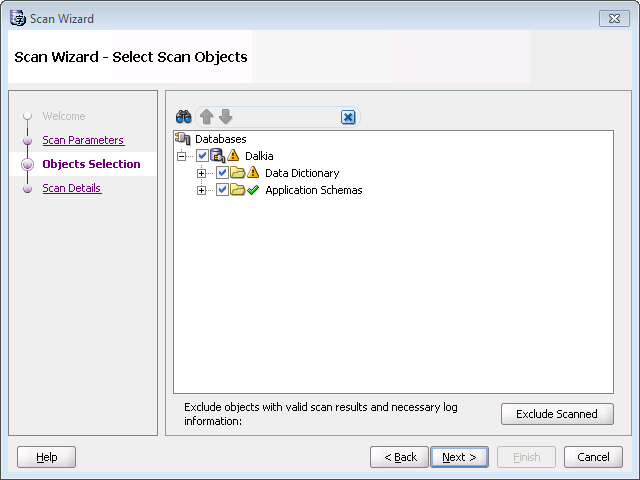
You scan the database for characters that you need to convert in order to make them display correctly in your new Unicode database. You should scan both the Data Dictionary and the Application Schemas.
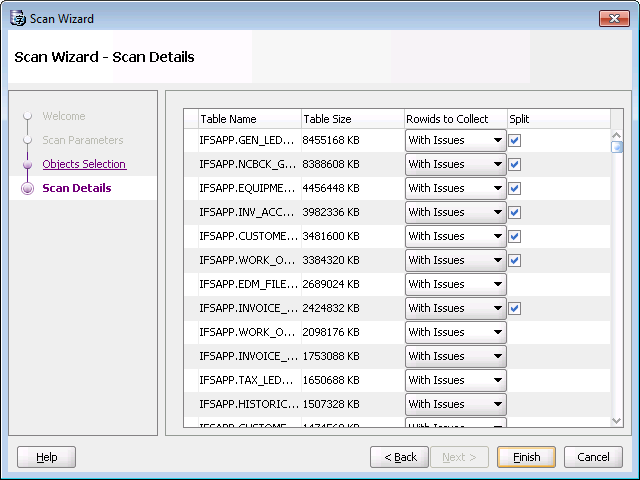
It is OK to use the default values.
After the scanning you can take a look at the data using the Database Scan Report...

Here you can see what your data looks like from a conversion to Unicode perspective:
- Need no change - no problem, don't need any conversion
- Need conversion - will be converted by DMU
- Invalid representation - needs to be fixed before converting the database. Use Cleansing Editor to edit the data
- Over column limit - This data will be longer than the column length today. You can fix this by changing the VARCHAR2 columns to use CHAR semantics instead of BYTE semantics. Use Bulk Cleansing Wizard
- Over type limit - This data will be longer than the column length even if you convert the column to CHAR semantics. This data needs to be shortened. Use SQL or Cleansing Editor to fix this problem.
You can also filter the data by using the filter combo box. The choices you have is:
- All - See everything
- Scanned - Objects with valid scan result
- Scan failed - See objects that failed during the scan
- Not scanned - See which objects that is not scanned
- Requiring no conversion - See which objects that contains data that requires no conversion
- Requiring conversion, without issues - See which objects with data that will be converted by DMU without any problem
- With invalid representation - See which objects that has invalid representations amongst their characters. These objects requires some action to change the invalid characters
- Exceed data type limit - Objects that has data that will exceed the data types limit after conversion
- Exceed column limit - Objects that has data that will exceed its column limit after conversion
- Not changeless - Objects that belongs to the previous described categories "Need Conversion", "Invalid representation", "Over column limit" or "Over type limit"
- With some issues - Displays objects that has data conversions that must be resolved before using DMU conversion. This is the most interesting filtering
Cleansing the data in the application¶
if your database scan reported any problems with your data you need to cleanse the data. When cleansing data in IFS Cloud you need to manually consider the following problems (the other problems will DMU handle):
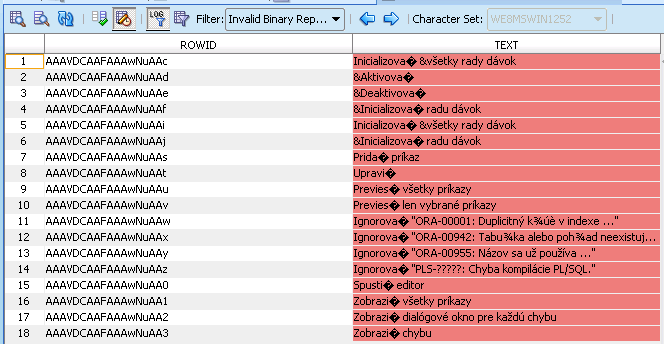
- Invalid binary representation
In this case you have a character in your database that can't be represented in the Unicode database, you need to change this character manually. An example on how to fix this is shown below. - Exceed data type limit
If you have some of these problems you need to manually shorten your string, because the Unicode expansion makes your string longer than what can be stored in the database. - Data Dictionary problem
If the Data Dictionary has problems of converting its data you need to manually handle these problems. It doesn't exist any clear direction of how to do it but below is one example of how to handle a specific problem.
Use Migration/Bulk Cleansing to convert all string columns to use CHAR semantics. This tool will help you to migrate all your strings with byte semantics to char semantics. Just start the wizard and check those schemas that you want to Bulk Cleanse.
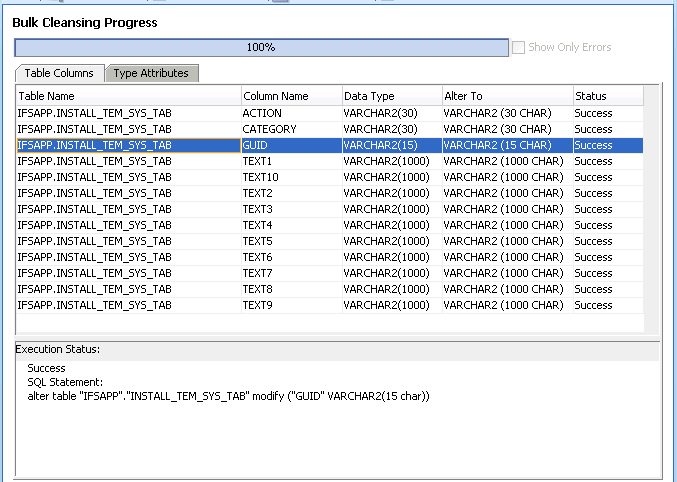
In the progress window you can see which changes that were made in this step.
This conversion can also be achieved on Application Owner objects by running the following SQL logged on as Application Owner:
BEGIN
Installation_Sys.Convert_Tables_To_Unicode('%');
END;
/
Use Cleansing Editor to cleanse the data that needs to be cleansed. Be sure to filter out the data you need to change. It is most important to cleanse data that is Exceeding Data Type Limit and data that has Invalid Binary Representation. Data that exceeds Column Limit is fixed with the Bulk Cleansing Wizard.
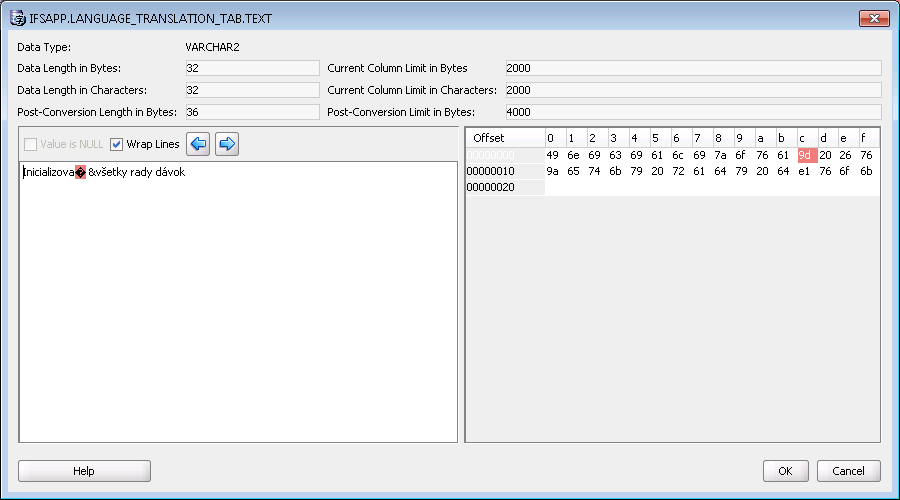
If you double-click on the red field you get an editor up where you can change your data. Don't forget to save your changes.
Cleansing the data in the Data Dictionary¶
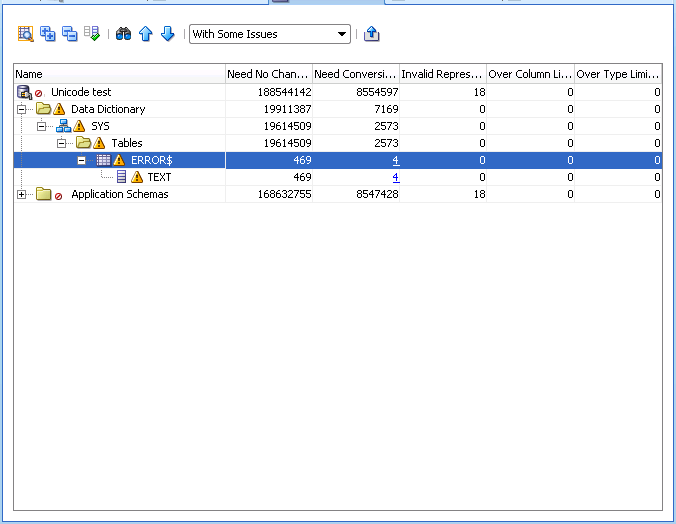
If you have data that requires conversion in the Data Dictionary you must fin a way to get rid of that data, since this data can not be manually cleansed. One example could be that you have a problem with special Swedish characters in the ERROR$ table.
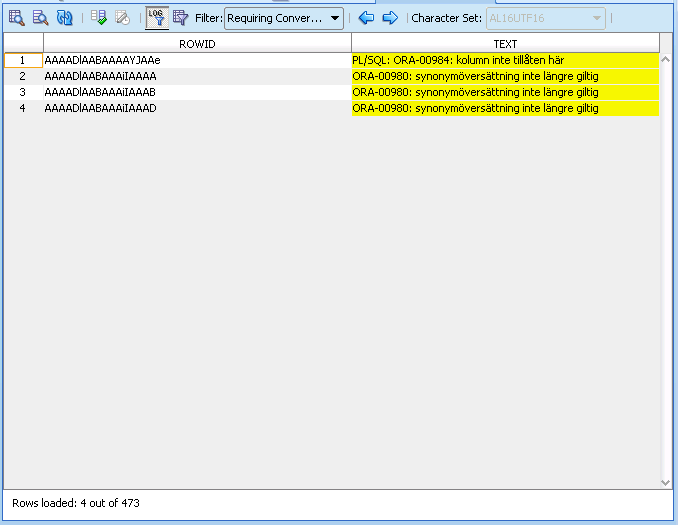
You can use this query to find out what is your table name and column name with the invalid data if you copy the rowid values from the Cleansing Editor.
SELECT d.object_type, d.owner, d.object_name
FROM dba_objects d, error$ c
WHERE d.object_id = c.obj#
AND c.rowid IN ('AAAADlAABAAAAYJAAe',
'AAAADlAABAAAiIAAAA',
'AAAADlAABAAAiIAAAB',
'AAAADlAABAAAiIAAAD');
These rows in ERROR$ can be removed by recompiling those objects with NLS_LANG set to AMERICAN_AMERICA.
In a worst case scenario you might need to drop some Database objects in order to get rid of some of the Data Dictionary problems.
Note: Oracle saves dropped objects in the recycle bin. These objects may be hard to find. If you want to get rid of the objects in the recyclebin enter:
PURGE DBA_RECYCLEBIN;in SQLPlus or similar tool.
Converting the database¶
Investigate all the steps that are going to be performed during the conversion of the database. When you are ready for conversion click the conversion button and run the conversion wizard.
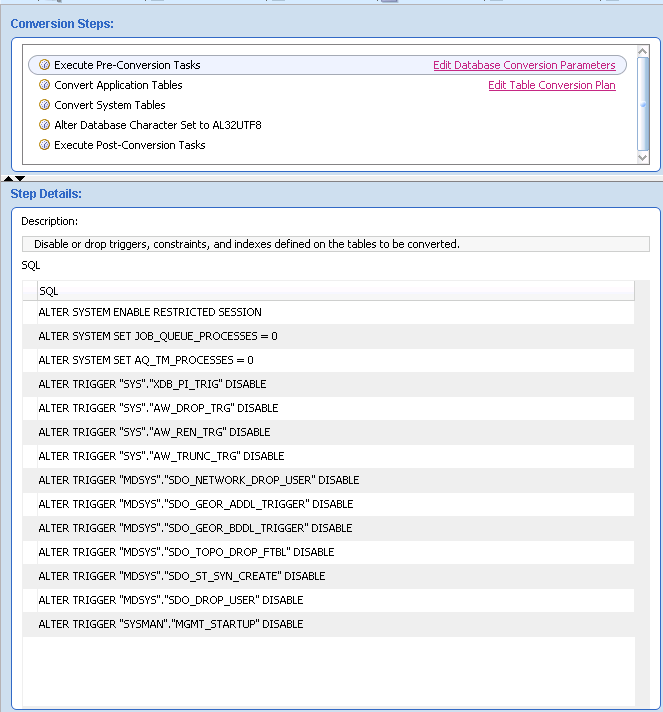
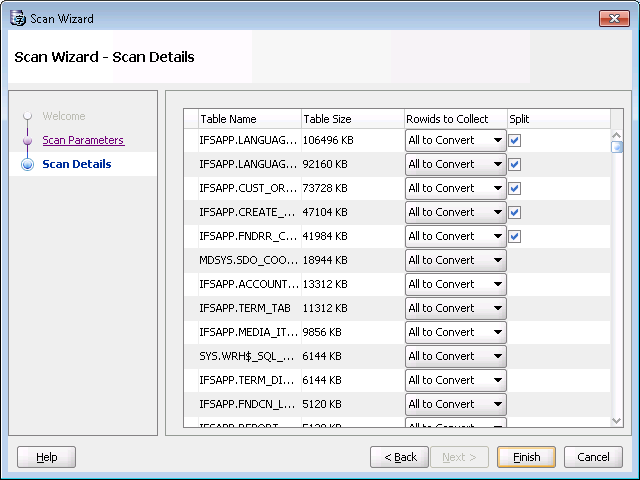
Follow the database conversion steps in DMU.
Validating data as Unicode¶
- Uninstall the repository and re-install it in validation mode.
- Scan the database.
- Check the database scan report so everything is OK.
Verify¶
 |
Verify by logging on the database with a IFS Enterprise Explorer client and save a non English character to see if it is stored and retrieved correctly. |
 |
Contact IFS support if you have problems. |